![]()
Just recently Alexandre Passant from DERI Galway went public with a new web service called seevl. First impressions after test driving the system reveal that the seevl team is keeping the promises they have made: “Seevl reinvents music discovery. We provide new ways to explore the cultural and musical universe of your favorite artists and to discover new ones by understanding how they are connected. In addition, we let you comment every piece of data about them.”
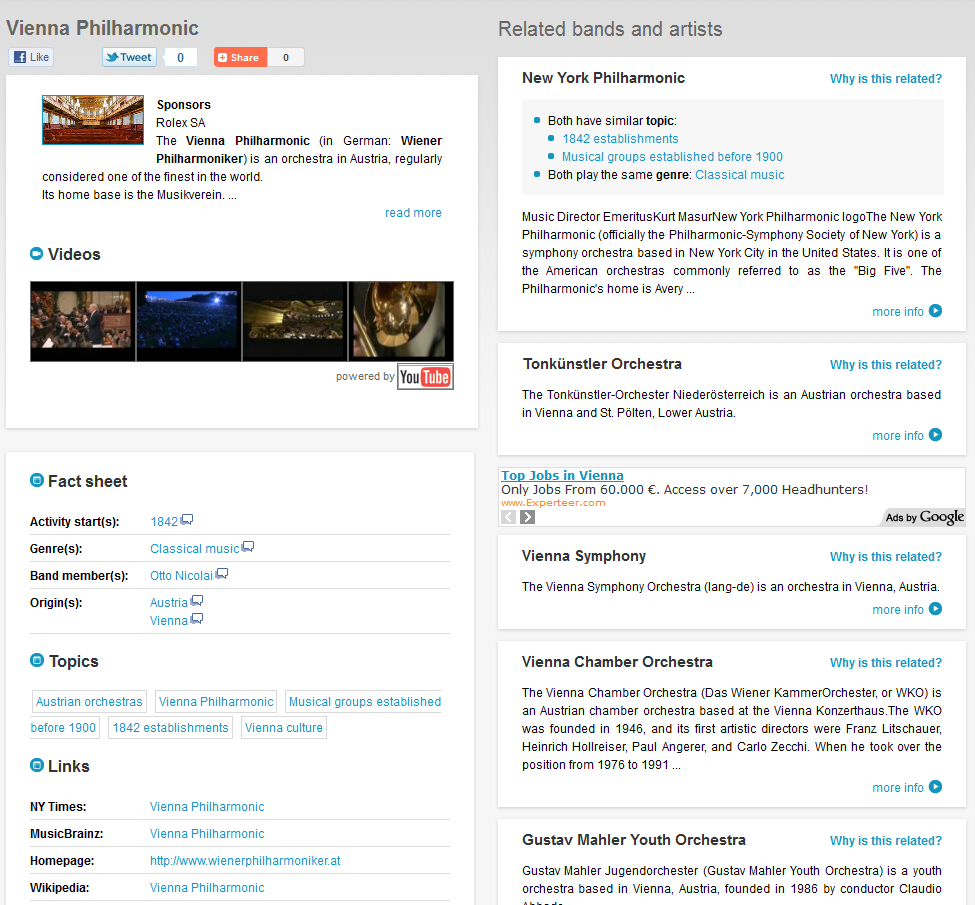
I was talking with Alexandre and asked a couple of questions:
Q: seevl.net aims to offer a new way of music recommendations. What exactly can the user expect from it?
The main idea is to offer context around the recommendations, while existing systems are opaque, or rely on collaborative filtering techniques. So that a user know why he could / should like X if he’s browsing page about Y. We hope (and we’ve seen it from our user feedback so far) that it can help to discover new bands and hidden connections.
Q: Yes, indeed this is something new. Maybe for the typical users this could be too complicated. This brilliant feature should somehow be hidden – working just like a magic button?
So far, we include this in the “why is related” button, but we’re constantly working on the UI / UX. Also, we only provide text for now, but are working on dataviz interfaces.
Q: seevl offers for developers a Web API. It seems like you don´t use semantic web standards for that?
We use content-negotiation to provide machine-readable data for every page (search results, entity description, related artists, etc.). If by non-SW standards you mean non-RDF, indeed, we provide JSON instead of RDF/XML or N3, etc. But our JSON integrates URI that you can dereference and follows a similar approach than other existing RDF-JSON serialisation. So, why JSON you may ask. Because our developer target is music hackers, and all APIs from this community (last.fm, echonest, etc.) offer JSON, not RDF. Learning a new JSON schema takes 5 min, learning RDF takes much more.
But we believe that a JSON-RDF serialisation combines the best of both worlds. Actually, we could say we provide our data using standards (we’re giving back a graph that follows the RDF abstract model, with links to dereferencable URIS) but not in a (so far) standardised serialisation.
Q: I agree. But mid-term oriented I would go additionally for SPARQL. A lot of people learn how to SPARQL at the moment.
Yes, we have to measure the cost / ROI. Complete SPARQL can lead to complex queries, that’s why they are somehow hidden behind our search interface (that basically construct a controlled SPARQL query). But that could be something provided to advanced customers.
Q: seevl.net is based on linked data sets like DBpedia, MusicBrainz or Freebase. Is seevl itself offering Linked (Open) Data? I can also see heavy use of the open graph protocol. How could a facebook application of seevl could look like?
Yes, we provide our data back at http://developers.seevl.net. We’re using the Music Ontology and a bit of other models (FOAF, etc.). So far, the OGP markup is used for Facebook likes – but we are looking at other things that could be built on top of this.
Q: Which business model are you following? Can one integrate your service into his shop? would you offer this a cloud service? for how much?
We’ll have B2C (new features on the website are coming soon) and a B2B freemium model. We’re currently identifying how much calls we can support as part of the free-calls per day (so that will indeed be cloud-based, our architecture is on EC2). So, integration of our service / data in shop websites, etc. is definitely what we’d like to see and to feature in our upcoming app-gallery ! The only requirement for data-reuse is attribution and linking-back to the service.
Thanks Alex, and I wish you and your team all the best with seevl.net!