![]() The Vienna-based company punkt. netServices is just about to release a demo version of their PoolParty service, a SKOS-based thesaurus management tool with linked data capabilities. I had the chance to pre-read a white paper and test their service. Here is a brief overview. You can also try a demo.
The Vienna-based company punkt. netServices is just about to release a demo version of their PoolParty service, a SKOS-based thesaurus management tool with linked data capabilities. I had the chance to pre-read a white paper and test their service. Here is a brief overview. You can also try a demo.
Purpose
Poolparty was conceived to facilitate various applications like
- Semantic search engines
- Recommender systems (similarity search)
- Corporate bookmarking
- Annotation- & tag recommender systems
- Autocomplete services and facetted browsing.
These use cases can be either achieved by using PoolParty stand-alone or by integrating it with existing Enterprise Search Engines and Document Management Systems or Enterprise Wikis.
Thesaurus Management
PoolParty is aiming to be easy to use for people without a strong Semantic Web background or special technical skills. The GUI is entirely web-based and utilizes AJAX so the user can e.g. quickly merge two concepts via drag & drop. An overview over the thesaurus can be gained with a tree or a graph view on the concepts.
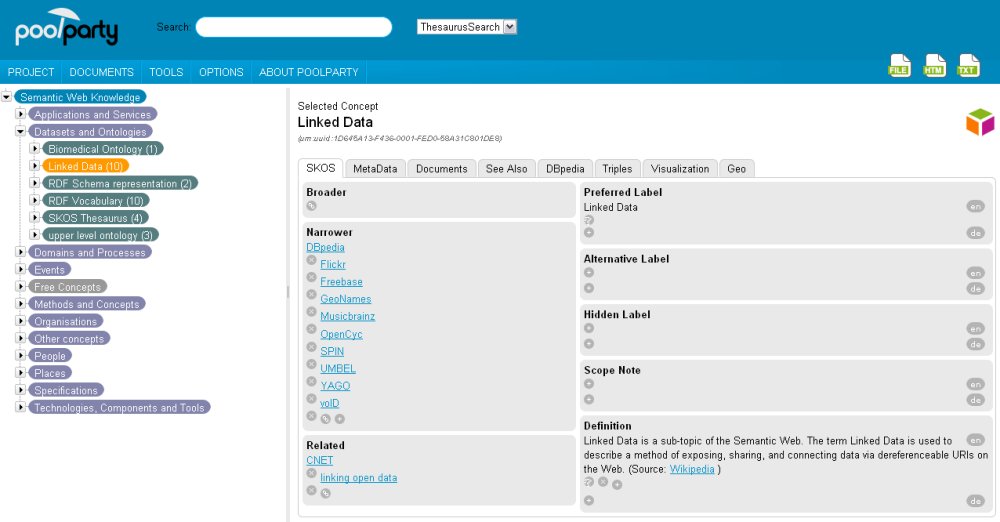
PoolParty also helps to semi-automatically add concepts to a thesaurus as it can be used to analyse documents (e.g. web pages or PDF files) relevant to a thesaurus’ domain in order to glean candidate terms. This is done by the key-phrase extractor of KEA. The extracted terms can be selected by the user, thereby becoming “free concepts” which later can be integrated into the thesaurus, turning them into “approved concepts”.
Documents can be searched in various ways – either by keyword search in the full text, by searching for their tags or by semantic search and similarity search. The latter takes not only a concept’s preferred label into account, but also its synonyms and the labels of its related concepts are considered in the search. The user might manually remove query terms used in semantic search. Boost values for the various relations considered in semantic search may also be adjusted. In the same way the recommendation mechanism for document similarity calculation works.
PoolParty by default also publishes a Semantic Wiki version of its thesauri, which provides an alternative way to browse and edit concepts. Through this feature anyone can get read access to a thesaurus, and optionally also edit, add or delete labels of concepts. Search and autocomplete functions are available here as well. The Wiki’s XHTML source is also enriched with RDFa, thereby exposing all RDF metadata associated with a concept to be picked up by RDF search engines and crawlers. (See two examples: Cocktail thesaurus & Standard Thesaurus for Economics)
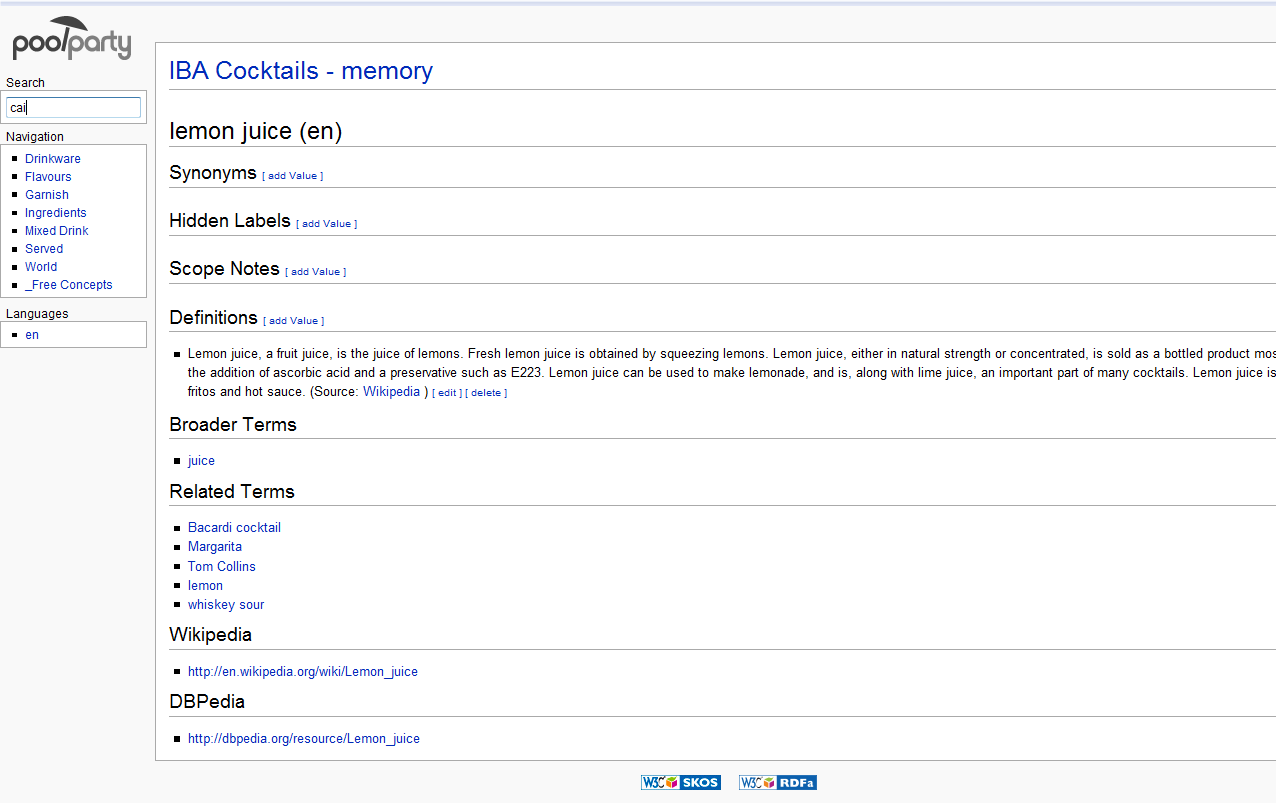
PoolParty also supports the import of thesauri in SKOS (including several consistency checks) or Zthes format. Those functionalities can also be consumed as stand-alone web services via PoolParty SKOS Services. Additionaly, lists of concepts and their labels can also be imported via CSV files.
Linked (Open) Data
PoolParty not only publishes its thesauri as Linked Open Data (in addition to a SPARQL endpoint), but it also consumes LOD in order to expand thesauri with information from LOD sources.
Concepts in the thesaurus can be linked to e.g. DBpedia via a service like Georgi Kobilarov‘s DBpedia lookup service, which takes the label of a concept and returns possible matching candidates. The system suggests relevant resources from DBpedia and the user can select the one that matches the concept from his thesaurus, thereby creating a skos:exactMatch relation between the concept URI in PoolParty and the DBpedia URI. The same approach can be used to link to other SKOS thesauri available as Linked Data.
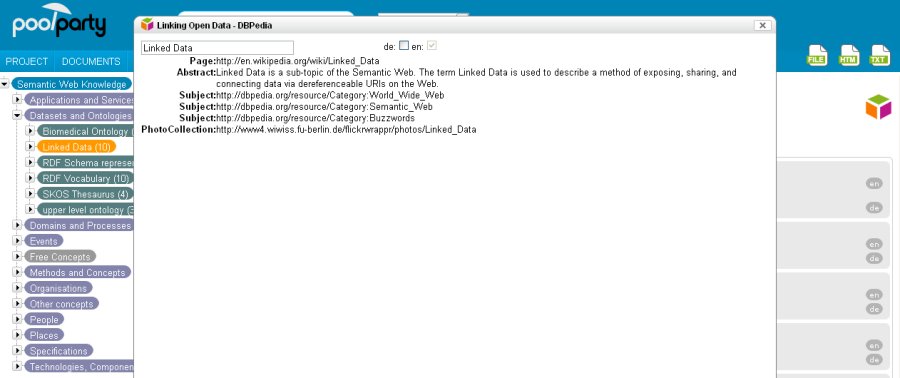
Other triples can also be retrieved from the target data source, e.g. the DBpedia abstract can become a skos:definition and geographical coordinates can be imported and be used to display the location of a concept on the map, where appropriate. The DBpedia category information may also be used to retrieve additional concepts of that category as siblings of the concept in focus, in order to populate the thesaurus.
PoolParty is capable of importing a SKOS thesaurus from a Linked Data server, and may also receive updates to thesauri imported this way. This feature has been implemented in the course of the KiWi project funded by the European Commission. KiWi also contains SKOS thesauri and exposes them as LOD. Both systems can read a thesaurus via the other’s LOD interfaces and may write it to their own store. This is facilitated by special Linked Data URIs that return e.g. all the top-concepts of a thesaurus, with pointers to the URIs of their narrower concepts, which allow other systems to retrieve a complete thesaurus through iterative dereferencing of concept URIs.
Additionally KiWi and PoolParty publish lists of concepts created, modified, merged or deleted within user specified time-frames. With this information the systems can learn about updates to one of their thesauri in an external system. They then can compare the versions of concepts in both stores and may write according updates to their own store.
This means each system decides autonomously which data it accepts and there is no risk of a system pushing data that might lead to inconsistencies into an external store. Data transfer and communication are achieved using REST/HTTP, no other protocols or middleware are necessary. Also no rights management for each external systems is needed, which otherwise would have to be configured separately for each source.
Technology
The software is written in Java and utilizes the SAIL API, so it can be used with various triple stores. The thesaurus management itself (viewing, creating and editing SKOS concepts and their relationships) can be done in an AJAX Frontend based on Yahoo User Interface (YUI). Editing of labels can alternatively be done in a Wiki style HTML frontend. For key-phrase extraction from documents PoolParty uses a modified version of the KEA 5 API, which is extended for the use of controlled vocabularies stored in a SAIL Repository (this module is available under GNU GPL). The analysed documents can be stored and indexed in Lucene/Solr or any other (enterprise) search system along with extracted and semantically related concepts.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=4251823d-5925-4c7d-8d67-e74c82af33f9)