In our recent endeavor to import in PoolParty the Google Product taxonomy in different languages, we encountered some challenges that needed to be addressed. The first challenge was that the Google Product taxonomy is in Excel (XLS) format, and for each language there is a separate file. The second challenge is on how to align and merge the data rows coming from different languages, i.e., how can we be sure that two entities in different languages (respectively different files) mean the very same thing. We did this exercise for two languages (English and German), but inductively the same methodology can be applied for arbitrary number of languages (here are links for Italian and French to name a few).
Google Product Taxonomy
Google Product Taxonomy is a taxonomy used by Google in categorizing products, for the purpose of ensuring that a certain advertisement is shown with the right search results. The taxonomy in Excel format (see the figure below) is organized in columns, where each column based on the order corresponds to a depth level in the taxonomy, so the first column corresponds to the highest level in the taxonomy — in SKOS that corresponds to a concept scheme; the second column corresponds to the second-highest level in the taxonomy — in SKOS that is a top concept; and the other columns represent concepts and their respective narrower concepts and so it goes on. As PoolParty supports XLS import, in order to import it, we had to slightly adjust the Google Product Taxonomy XLS file. For this we used OpenRefine (formerly known as Google Refine), a powerful data wrangling tool.
Data wrangling with OpenRefine
The Excel data from Google Product Taxonomy was almost perfect to be imported in PoolParty, with a single caveat, the duplicates — as can be seen in the following figure — have to be removed. One can see that whenever a new level in the taxonomy is introduced using a new column data, the previous column data records are duplicated.
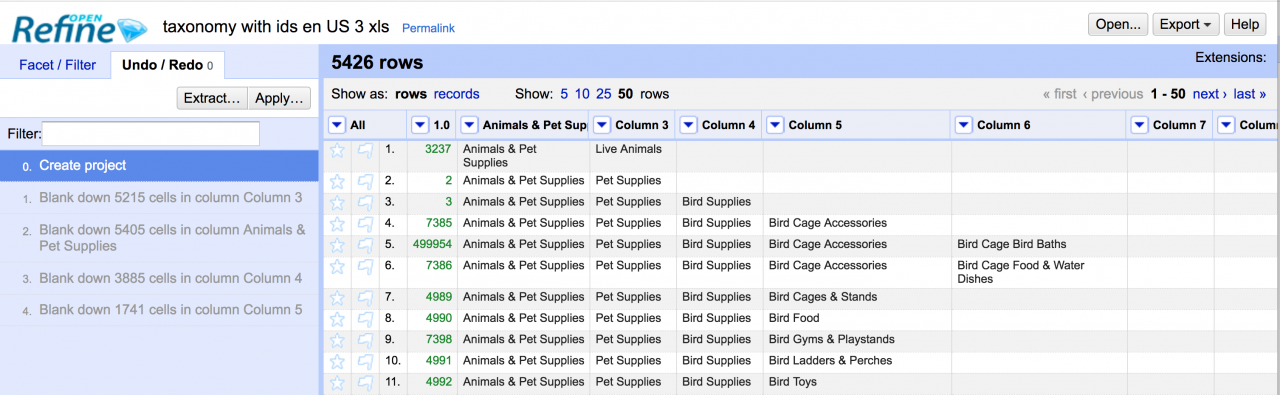
In PoolParty one needs to remove such recurring cell values, but keep only the top-most value for each different concept. Also, one has to rename the columns such that the first column is called “scheme”, the second “concept”, likewise the third “concept” and so on. Thus, it has to look like the following figure (note: OpenRefine internally renames columns with the same name in order to distinguish them visually, thus introduced concept2, concept3,…).
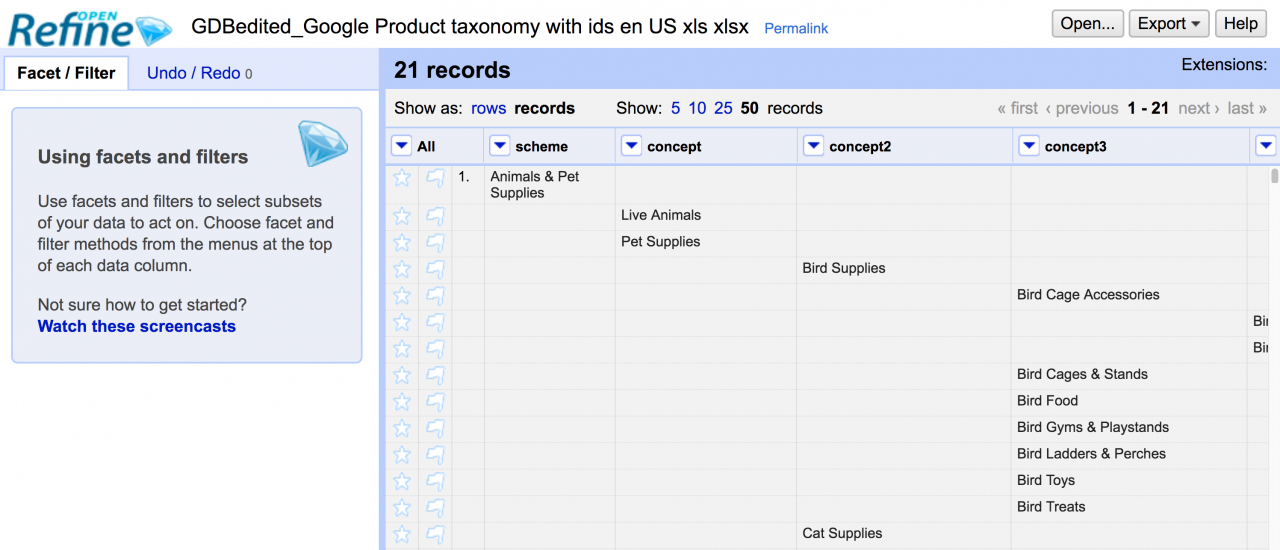
One can see that all duplicates under “Animals & Pet Supplies” are removed, same it is done with the column “Live Animals” and “Pet Supplies” and so on.
This transformation was done using OpenRefine’s “blank down” feature, by just going through each column and selecting Edit Cells -> Blank down. As result, all the duplicates are removed as in the previous figure, and data is ready to be imported in PoolParty. The same procedure is done for the German version as well.
PoolParty Import/Export
As mentioned earlier, PoolParty supports the feature to import XLS data. It also supports export to RDF feature that allows one to choose from a range of export options with the ultimate aim of providing you a means to avoid data lock-in. Export to XLS is also possible. Once the data are imported they are internally stored in RDF format. Using RDF format is much easier to do data integration, where each resource is assigned an unique URI. For both English and German the corresponding XLS files are imported to PoolParty. Import Assistant in PoolParty gives us a green light, suggesting that all the SKOS constraints are satisfied. Once we have import them, for each language, we export data as RDF, so that we can do the merging.
Import RDF data to a triplestore
Both RDF data belonging to the English and German version of the Google Product Taxonomy, were imported to a dedicated triple store. Now, the question is how to align the RDF data consisting of statements in different languages? One, for instance, could think of doing a “string matching” by using machine translation beforehand for non-English languages, but as we know the precision is not always 100% correct. Luckily for us, in each of the XLS files, there is a “notation” column, such that each row has a corresponding “identifier”. This is translated to skos:notation when imported to PoolParty. Now we are sure which row in English corresponds to the German based on the notation, this is because they coincide.
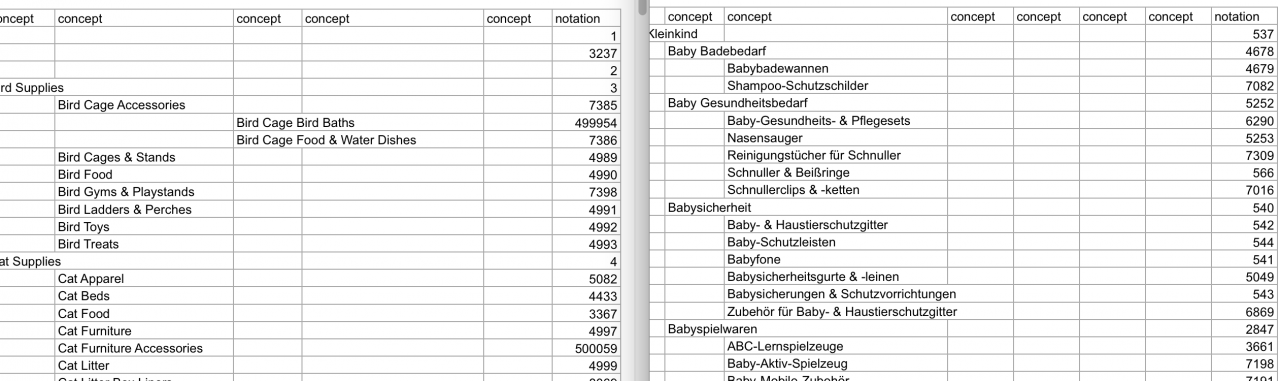
In the case of RDF, we align the data on skos:notation identifiers, and for this we use a SPARQL query.
Data merging using SPARQL
Merging RDF data based on skos:notation is done relatively easy, using the following SPARQL query:
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
insert { graph <https://nextrelease.poolparty.biz/GoogleProductTaxonomy11-2017/thesaurus> {?s2 skos:prefLabel ?label1 . }}
where {
?s1 skos:notation ?o1 . ?s1 skos:prefLabel ?label1 .
?s2 skos:notation ?o2 . ?s2 skos:prefLabel ?label2 .
FILTER (?o1 = ?o2 && !sameTerm(?s1, ?s2))
}
The query checks for all different subjects that have the same notation, and for each result, inserts the corresponding label. Now, in the graph we have concepts that have skos:prefLabel for both English and German.
Import final (graph) data to PoolParty
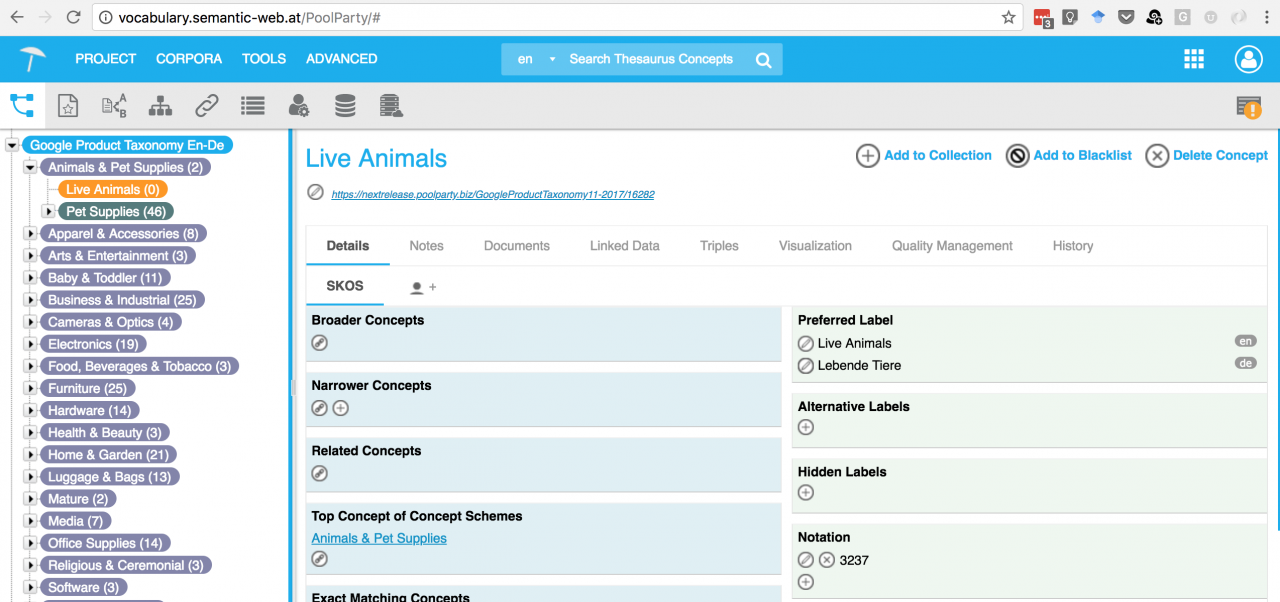
The resulting RDF graph data was imported to PoolParty, where now for each concept we have both labels in English and German. In the following figure, one can see this under Preferred Label. Note that in SKOS one can have multiple preferred labels, as long as they are in different languages.
Conclusion
We could have done this exercise without using OpenRefine, but then we would have done a manual work on the 5426 rows, going through each column and removing the duplicates. For large files, the approach using OpenRefine is indispensable and too many times saved us a lot of precious time. Same can be said for SPARQL, we automated the merge of the data by using a simple SPARQL query instead of doing that work manually. As conclusion, we can claim that data wrangling with OpenRefine, PoolParty and SPARQL proved to be a huge time saver, just imagine if you have to do this exercise for n different languages.