With technology being number one concern for most businesses, there is an increasing need for better lifecycle management of software and data engineering processes. Quality management is a critical component, especially nowadays with the explosion of big data sources and existing tools that tend to break at scale.
In the case of semantic knowledge bases, data quality comes hand in hand with a consistent knowledge graph. Managing data inconsistencies is a data engineering task supported by software solutions.
With this in mind, we wanted to align data management and software development in our flagship product PoolParty semantic suite. Therefore, we pursue a holistic approach from where both PoolParty users and our software developers will benefit from new features to facilitate their workflow and increase the quality of outcomes.
As a result, we developed the Smart Development Assistant (SDA) that supports software and data engineering processes in PoolParty in a very intuitive way. This process was part of the ALIGNED research project, a collaboration between the Semantic Web Company and prestigious universities, information companies, and academic curators.
At the end of the project, we were able to take our software to the next level by increasing the productivity of our development team and hence improving client satisfaction.
In this post, I am going to break down how we developed the Smart Development Assistant and how semantic technologies supported us in our use case.
What was the challenge?
Semantic technologies are largely based on the Resource Description Framework (RDF), which allows connecting structured and unstructured data from disparate systems.
Semantic web applications like PoolParty Semantic Suite enable the import of RDF based vocabularies into smart applications like semantic search and content tagging.
As opposed to relational databases, semantic web databases have no fixed schema. Thus, there is no way to guarantee consistency of the imported datasets.
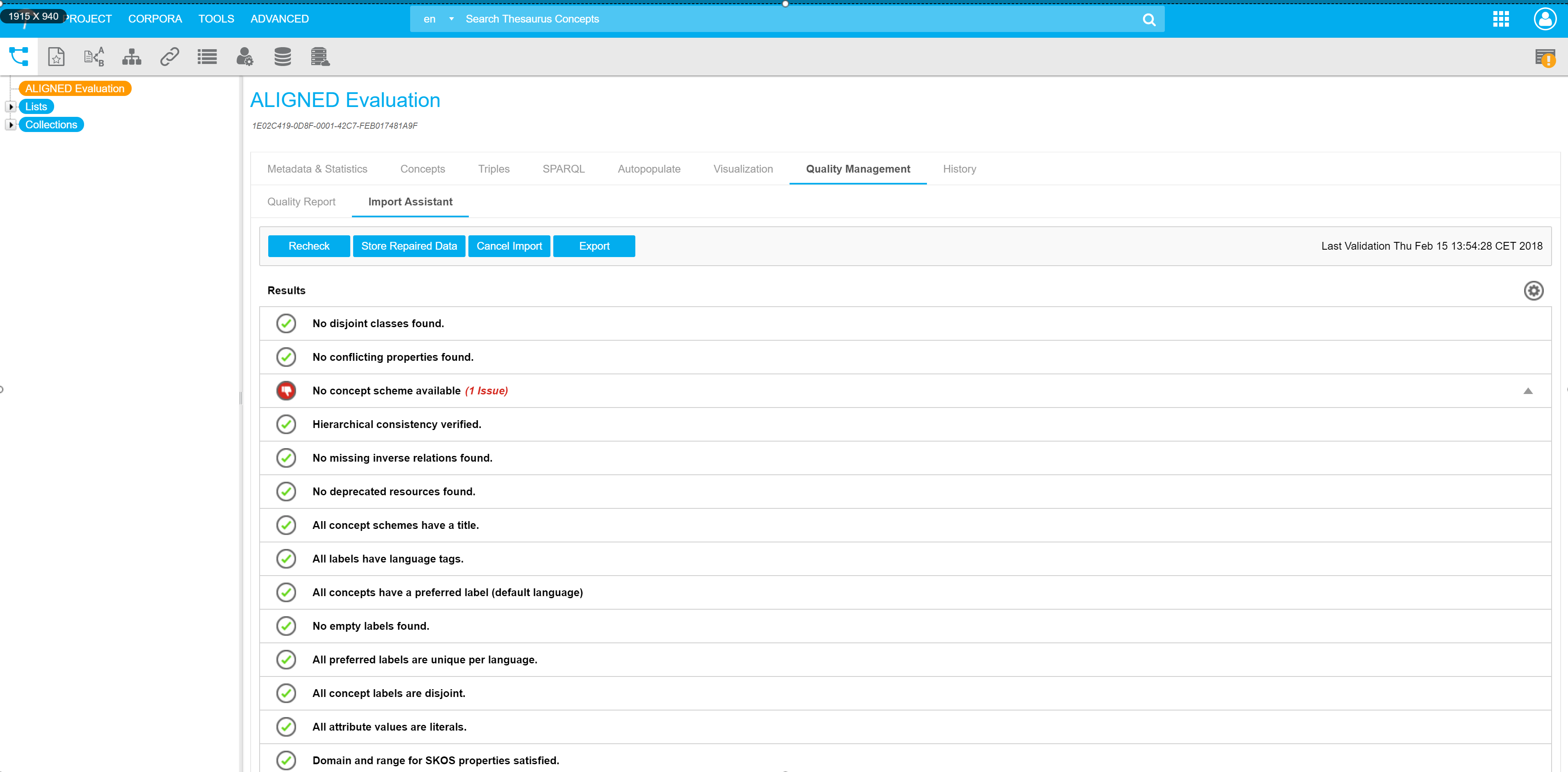
When importing an RDF dataset into PoolParty we have to ensure that it satisfies constraints for the application to work correctly. These restrictions correspond to our data model which is based on SKOS (a simple knowledge model for expressing controlled vocabularies).
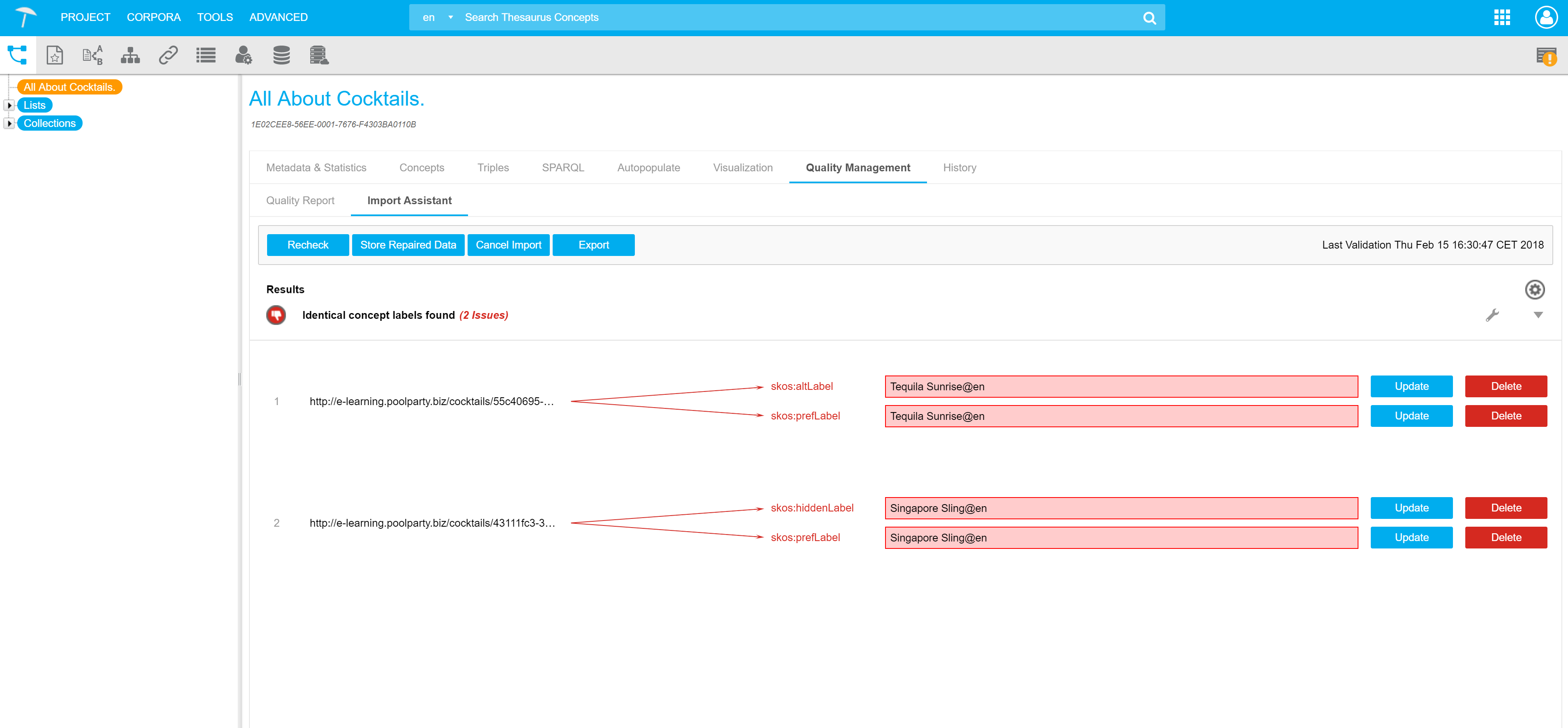
For example, a typical issue is when the preferred label (a lexical label that represents the meaning of a concept) and the alternative label (acronyms, abbreviations, spelling variants, etc.) of a concept are the same. Without a quality check, this inconsistency will remain and affect the quality of outputs.
What is the solution?
To overcome challenges as mentioned above and mitigate subsequent problems, we developed the Smart Development Assistant built on top of semantic technologies.
We defined a set of 16 constraints based on SKOS, SHACL shapes, and SPARQL queries which allow us to identify data inconsistencies caused by application errors or introduced by a user while importing data into PoolParty.
The Smart Development Assistant automatically executes an RDF validation and offers repair strategies for data curation that the user can immediately implement. After solving detected violations, the user can store the new data into the PoolParty project.
By ensuring data consistency, we can avoid many problems; still, some errors will persist. In such a case, the user depends on the software development team to solve bug issues.
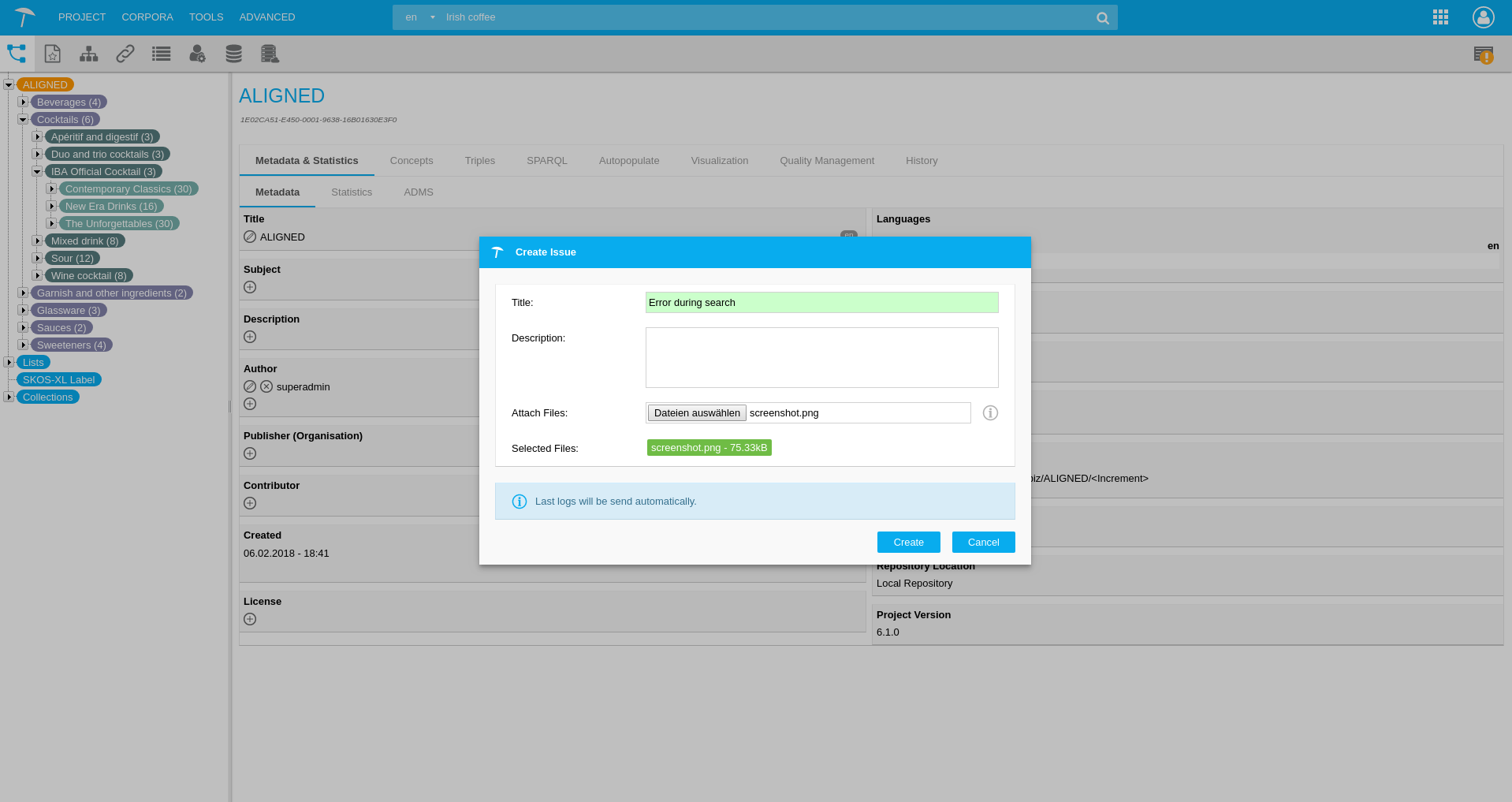
With the Smart Development Assistant, we also allow the user to create a bug ticket automatically without leaving the semantic platform.
The development team will directly receive a notification to solve the ticket. This way, we are aligning data and software engineering processes with a simple tool that improves the user experience with PoolParty and helps developers to work more efficiently.
We also integrated the Smart Development Assistant with PoolParty GraphSearch. GraphSearch is a front-end application with search, recommendation and analytics functionalities.
The development team can analyze the incoming tickets in a user-friendly interface. They can search by issue type or assignee, or a mixture of both, just to name an example.
A similarity computation detects duplicate bugs and finds associated stories and requirements. The team can also access statistical charts and histograms for analysis purposes.
For more details watch the video.
Which PoolParty components did we use for developing the Smart Development Assistant?
I will now introduce you to the PoolParty semantic suite capabilities and the technology components we used for the Smart Development Assistant.
PoolParty Thesaurus Server
The PoolParty Thesaurus Server supports web-based taxonomy and ontology management, which are the cornerstone of any application based on semantic technologies. PoolParty Thesaurus Server allows users to create and edit controlled vocabularies based on the SKOS scheme and organizes it in a tree-like structure.
To develop the Smart Development Assistant, we imported the ALIGNED generic metamodel (an outcome of the research project we participated in) to the thesaurus server and extended it to fit our use case, resulting in the PoolParty design intent ontology. With this ontology, we were able to integrate datasets generated through requirements specification and the issues raised during their implementation.
PoolParty GraphSearch
With PoolParty GraphSearch organizations can connect content and data repositories to improve search over a variety of business objects and analyze the data on a granular level. You can enhance GraphSearch with recommendation algorithms providing similarity-based recommendations or a matchmaking algorithm.
Our development team is using the GraphSearch application of the Smart Development Assistant on a daily basis. It assists them in managing software development artifacts: detecting duplicate bugs, finding stories associated with a specific issue, visualizing statistics on time to issue resolution and keeping track on the number of bugs over the time.
Read the white paper for more insights on PoolParty GraphSearch.
PoolParty Unified Views
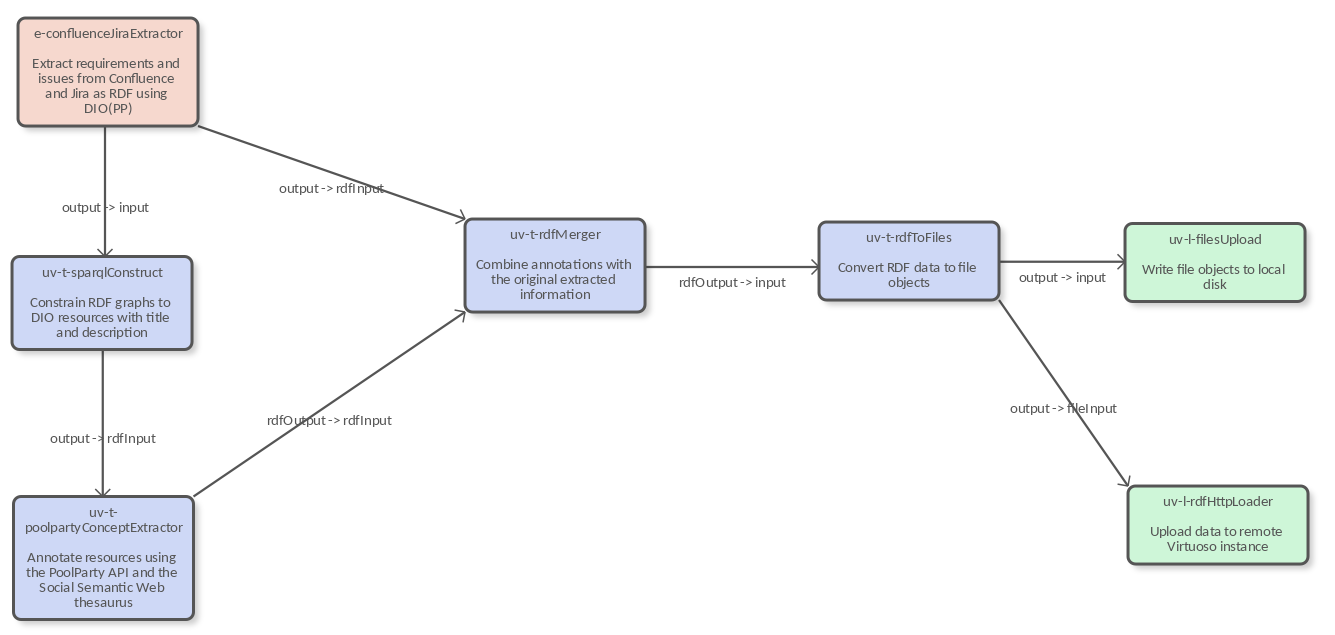
PoolParty UnifiedViews provides a framework to develop, execute, monitor, debug, schedule, and share RDF data processing tasks. Data processing tasks are modeled as pipelines via a graphical interface and can consist of several Data Processing Units (DPUs).
We created a UnifiedViews pipeline for harvesting data from two data repositories we use for software development (Confluence and Jira in our case) and transform it into RDF based on the PoolParty design intent ontology. Afterwards, we annotated the data using the PoolParty Knowledge Graph which helped on calculating similarity scores on issues and requirements.
Conclusion
Semantic technologies offer an array of solutions for entity-centric information architecture.
By considering features our partners and customers requested in several times, we took our product to the next level and increased the productivity of our development team.
Using PoolParty ontology management tool and integrated components such as GraphSearch and UnifiedViews, we delivered a cutting-edge solution for typical data and software engineering challenges in PoolParty Semantic Suite.
Our research and development team is looking forward to furthering developments supported by research funds and new partners.
Are you willing to partner with us to develop smart applications based on semantic technologies?
If so, don’t hesitate to contact us.
About the ALIGNED Project
Since 2004 the Semantic Web Company invests in research and innovation projects that have a direct impact on the development of our flagship product PoolParty Semantic Suite. This year we successfully finished the ALIGNED Project after three years of collaboration between industry and academia and €4 million of funding from the European Commission’s Horizon 2020 program. Several partners joined forces to develop new ways to build and maintain IT systems that use big data on the web.
The Smart Development Assistant was the PoolParty use case within the ALIGNED project. But there were many other use cases in a wide range of areas that showed how the latest semantic technologies could help create smarter legal information systems, provide better management of health data and help construct high-quality archaeological and historical datasets. In all of these areas people are struggling to harness the available data, and in all of these areas, ALIGNED’s semantic and model-driven technologies were able to help.