The Linked Data Lexicography for High-End Language Technology (LDL4HELTA) project was started in cooperation between Semantic Web Company (SWC) and K Dictionaries. LDL4HELTA combines lexicography and Language Technology with semantic technologies and Linked (Open) Data mechanisms and technologies. One of the implementation steps of the project is to create a language graph from the dictionary data.
The input data, described further, is a Spanish dictionary core translated into multiple languages and available in XML format. This data should be triplified (which means to be converted to RDF – Resource Description Framework) for several purposes, including to enrich it with external resources. The triplified data needs to comply with Semantic Web principles.
To get from a dictionary’s XML format to its triples, I learned that you must have a model. One piece of the sketched model, representing two Spanish words which have senses that relate to each other, is presented in Figure 1.
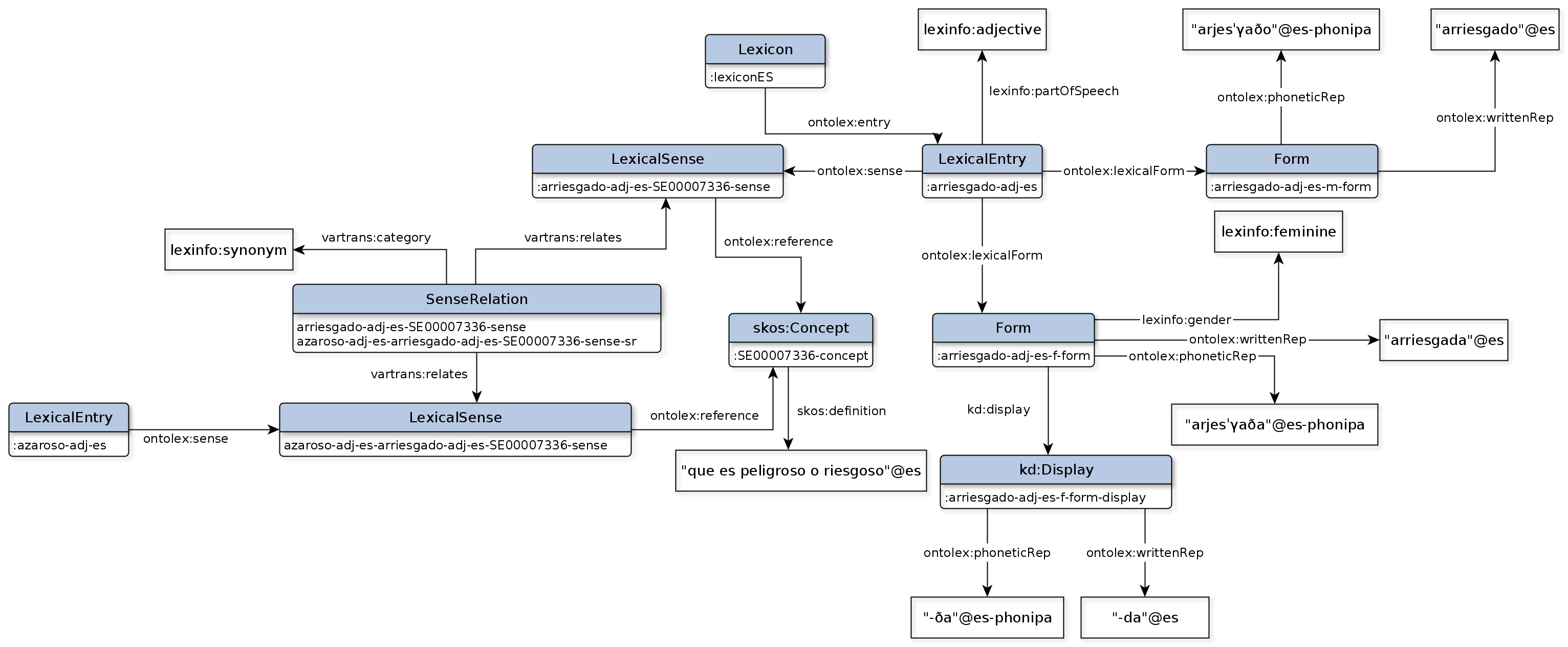
This sketched model first needs to be created by a linguist who understands both the language complexity and Semantic Web principles. The extensive model [1] was developed at the Ontology Engineering Group of the Universidad Politécnica de Madrid (UPM).
Language is very complex. With this we all agree! How complex it really is, is probably often underestimated, especially when you need to model all its details and triplify it.
So why is the task so complex?
To start with, the XML structure is complex in itself, as it contains nested structures. Each word constitutes an entry. One single entry can contain information about:
|
|
Entries can have predefined values, which can recur but their fields can also have so-called free values, which can vary too. Such fields are:
- Aspect
- Tense
- Subcategorization
- Subject Field
- Mood
- Grammatical Gender
- Geographical Usage
- Case
- and more…
As mentioned above, in order to triplify a dictionary one needs to have a clear defined model. Usually, when modelling linked data or just RDF it is important to make use of existing models and schemas to enable easier and more efficient use and integration. One well-known lexicon model is Lemon. Lemon contains good pieces of information to cover our dictionary needs, but not all of them. We started using also the Ontolex model, which is much more complex and is considered to be the evolution of Lemon. However, some pieces of information were still missing, so we created an additional ontology to cover all missing corners and catch the specific details that did not overlap with the Ontolex model (such as the free values).
An additional level of complexity was the need to identify exactly the missing pieces in Ontolex model and its modules and create the part for the missing information. This was part of creating the dictionary’s model which we calledontolexKD.
As a developer you never sit down to think about all the senses or meanings or translations of a word (except if you specialize in linguistics), so just to understand the complexity was a revelation for me. And still, each dictionary contains information that is specific to it and which needs to be identified and understood.
The process used in order to do the mapping consists of several steps. Imagine this as a processing pipeline which manipulates the XML data. UnifiedViews is an ETL tool, specialized in the management of RDF data, in which you can configure your own processing pipeline. One of its use cases is to triplify different data formats. I used it to map XML to RDF and upload it into a triple store. Of course this particular task can also be achieved with other such tools or methods for that matter. In UnifiedViews the processing pipeline resembles what appears in Figure 2.
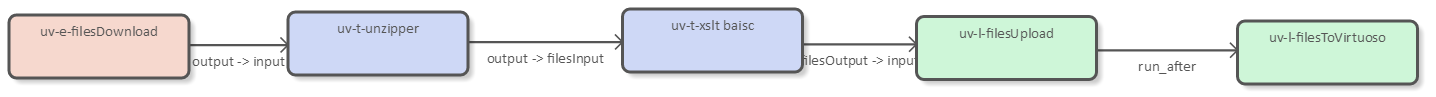
The pipeline is composed out of data processing units (DPUs) which communicate iteratively. In a left-to-right order the process in Figure 2 represents:
- A DPU used to upload the XML files into UnifiedViews for further processing;
- A DPU which transforms XML data to RDF using XSLT. The style sheet is part of the configuration of the unit;
- The .rdf generated files are stored on the filesystem;
- And, finally, the .rdf generated files are uploaded into a triple store, such as Virtuoso Universal server.
Basically the XML is transformed using XSLT.
Complexity increases also through the URIs (Uniform Resource Identifier) that are needed for mapping the information in the dictionary, because with Linked Data any resource should have a clearly identified and persistent identifier! The start was to represent a single word (headword) under a desired namespace and build on it to associate it with its part of speech, grammatical number, grammatical gender, definition, translation – just to begin with.
The base URIs follow the best practices recommended in the ISA study on persistent URIs following the pattern:http://{domain}/{type}/{concept}/{reference}.
An example of such URIs for the forms of a headword is:
- http://kdictionaries.com/id/lexiconES/entendedor-n-m-sg-form
- http://kdictionaries.com/id/lexiconES/entendedor-n-f-sg-form
These two URIs represent the singular masculine and singular feminine forms of the Spanish word entendedor.
- http://kdictionaries.com/id/lexiconES/entendedor-adj-form-1
- http://kdictionaries.com/id/lexiconES/entendedor-adj-form-2
If the dictionary contains two different adjectival endings, as with entendedor which has different endings for the feminine and masculine forms (entendedora and entendedor), and they are not explicitly mentioned in the dictionary than we use numbers in the URI to describe them. If the gener would be explicitly mentioned the URIs would be:
- http://kdictionaries.com/id/lexiconES/entendedor-adj-form
- http://kdictionaries.com/id/lexiconES/entendedora-adj-form
In addition, we should consider that the aim of triplifying the XML was for all these headwords with senses, forms and translations, to connect and be identified and linked following Semantic Web principles. The actual overlap and linking of the dictionary resources remains open. A second step for improving the triplification and mapping similar entries, if possible at all, still needs to be carried out. As an example, let’s take two dictionaries, say German, which contain a translation into English and an English dictionary which also contains translations into German. We get the following translations:
Bank – bank – German to English
bank – Bank – English to German
The URI of the translation from German to English was designed to look like:
And the translation from English to German would be:
In this case both represent the same translation but have different URIs because they were generated from different dictionaries (mind the translation order). These should be mapped so as to represent the same concept, theoretically, or should they not?
The word Bank in German can mean either a bench or a bank in English. When I translate both English senses back into German I get again the word Bank, but I cannot be sure which sense I translate unless the sense id is in the URI, hence the SE00006110 and SE00006116. It is important to keep the order of translation (target-source) but later map the fact that both translations refer to the same sense, same concept. This is difficult to establish automatically. It is hard even for a human sometimes.
One of the last steps of complexity was to develop a generic XSLT which can triplify all the different languages of this dictionary series and store the complete data in a triple store. The question remains: is the design of such a universal XSLT possible while taking into account the differences in languages or the differences in dictionaries?
The task at hand is not completed from the point of view of enabling the dictionary to benefit from Semantic Web principles yet. The linguist is probably the first one who can conceptualize “the how to do this”.
As a next step we will improve the Linked Data created so far and bring it to the status of a good linked language graph by enriching the RDF data with additional information, such as the history of a term or additional grammatical information etc.
References:
[1] J. Bosque-Gil, J. Gracia, E. Montiel-Ponsoda, and G. Aguado-de Cea, “Modelling multilingual lexicographic resources for the web of data: the k dictionaries case,” in Proc. of GLOBALEX’16 workshop at LREC’15, Portoroz, Slovenia, May 2016.