The ongoing debate around the question whether ‘there is money in linked data or not’ has now been formulated more poignantly by Prateek Jain (one of the authors of the original article) recently: He is asking, ‘why linked open data hasn’t been used that much so far besides for research projects?‘.
I believe there are two reasons (amongst others) for the low uptake of LOD in non-academic settings which haven’t been discussed in detail until today:
1. The LOD cloud covers mainly ‘general knowledge‘ in contrast to ‘domain knowledge‘
Since most organizations live on their internal knowledge which they combine intelligently with very specific (and most often publicly available) knowledge (and data), they would benefit from LOD only if certain domains were covered. A frequently quoted ‘best practice’ for LOD is that portion of data sets which is available at Bio2RDF. This part of the LOD cloud has been used again and again by the life sciences industry due to its specific information and its highly active maintainers.
We need more ‘micro LOD clouds’ like this.
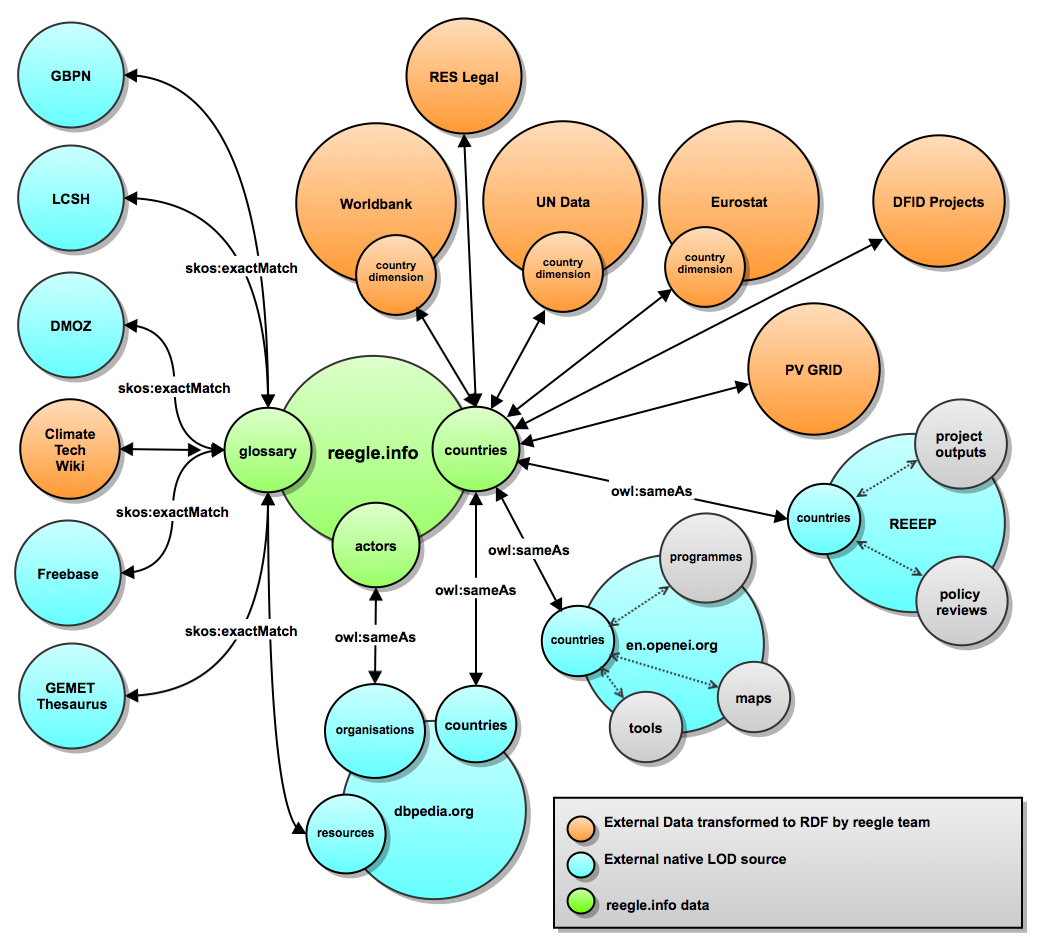
Another example for such is the one which represents the German Library Linked Open Data Cloud (thanks to Adrian Pohl for this pointer!) or the Clean Energy Linked Open Data Cloud:
I believe that the first generation of LOD cloud has done a great job. It has visualised the general principles of linked data and was able to communicate the idea behind. It even helped – at least in the very first versions of it – to identify possibly interesting data sets. And most of all: it showed how fast the cloud was growing and attracted a lot of attention.
But now it’s time to clean up:
A first step should be to make a clear distinction between the section of the LOD cloud which is open and which is not. Datasets without licenses should be marked explicitly, because those are the ones which are most problematic for commercial use, not the ones which are not open.
A second improvement could be made by making some quality criteria clearly visible. I believe that the most important one is about maintenance and authorship: Who takes responsibility for the quality and trustworthiness of the data? Who exactly is the maintainer?
This brings me to the second and most important reason for the low uptake of LOD in commercial applications:
2. Most datasets of the LOD cloud are maintained by a single person or by nobody at all (at least as stated on datahub.io)
Would you integrate a web service which is provided by a single, maybe private person into a (core-)application of your company? Wouldn’t you prefer to work with data and services provided by a legal entity which has high reputation at least in its own knowledge domain? We all know: data has very little value if it’s not maintained in a professional manner. An example for a ‘good practice’ is the integrated authority file provided by German National Library. I think this is a trustworthy source, isn’t it? And we can expect that it will be maintained in the future.
It’s not the data only which is linked in a LOD cloud, most of all it’s the people and organizations ‘behind the datasets’ that will be linked and will co-operate and communicate based on their datasets. They will create on top of their joint data infrastructure efficient collaboration platforms, like the one in the area of clean energy – the ‘Trusted Clean Energy LOD Cloud‘:

REEEP and its reegle-LD platform has become a central hub in the clean energy community. Not only data-wise but also as an important cooperation partner in a network of NGOs and other types of stakeholders which promote clean energy globally.
Linked Data has become the basis for more effective communication in that sector.
To sum up: To publish LOD which is interesting for the usage beyond research projects, datasets should be specific and trustworthy (another example is the German labor law thesaurus by Wolters Kluwer). I am not saying that datasets like DBpedia are waivable. They serve as important hubs in the LOD cloud, but for non-academic projects based on LOD we need an additional layer of linked open datasets, the Trusted LOD cloud.