In 2012 Jem Rayfield released an insightful post about the BBC’s Linked Data strategy during the Olympic Games 2012. In this post he coined the term “Dynamic Semantic Publishing”, referring to
“the technology strategy the BBC Future Media department is using to evolve from a relational content model and static publishing framework towards a fully dynamic semantic publishing (DSP) architecture.”
According to Rayfield this approach is characterized by
“a technical architecture that combines a document/content store with a triple-store proves an excellent data and metadata persistence layer for the BBC Sport site and indeed future builds including BBC News mobile.”
The technological characteristics are further described as …
- A triple-store that provides a concise, accurate and clean implementation methodology for describing domain knowledge models.
- An RDF graph approach that provides ultimate modelling expressivity, with the added advantage of deductive reasoning.
- SPARQL to simplify domain queries, with the associated underlying RDF schema being more flexible than a corresponding SQL/RDBMS approach.
- A document/content store that provides schema flexibility; schema independent storage; versioning, and search and query facilities across atomic content objects.
- Combining a model expressed as RDF to reference content objects in a scalable document/content-store provides a persistence layer that uses the best of both technical approaches.
So what are actually the benefits of Linked Data from a non-technical perspective?
Benefits of Linked (Meta)Data
Semantic interoperability is crucial in building cost efficient IT systems that integrate numerous data sources. Since 2009 the Linked Data paradigm has emerged as a light weight approach to improve data portability ferderated IT systems. By building on Semantic Web standards the Linked Data approach offers significant benefits compared to conventional data integration approaches. These are according to Auer [1]:
- De-referencability. IRIs are not just used for identifying entities, but since they can be used in the same way as URLs they also enable locating and retrieving resources describing and representing these entities on the Web.
- Coherence. When an RDF triple contains IRIs from different namespaces in subject and object position, this triple basically establishes a link between the entity identified by the subject (and described in the source dataset using namespace A) with the entity identified by the object (described in the target dataset using namespace B). Through these typed RDF links, data items are effectively interlinked.
- Integrability. Since all Linked Data sources share the RDF data model, which is based on a single mechanism for representing information, it is very easy to attain a syntactic and simple semantic integration of different Linked Data sets. A higher-level semantic integration can be achieved by employing schema and instance matching techniques and expressing found matches again as alignments of RDF vocabularies and ontologies in terms of additional triple facts.
- Timeliness. Publishing and updating Linked Data is relatively simple thus facilitating a timely availability. In addition, once a Linked Data source is updated it is straightforward to access and use the updated data source, since time consuming and error prune extraction, transformation and loading is not required.
On top of these technological principles Linked Data promises to improve the reusability and richness (in terms of depth and broadness) of content thus adding significant value to the content value chain.
Linked Data in the Content Value Chain
According to Cisco communication within electronic networks has become increasingly content-centric. I.e. Cisco reports for the time period from 2011 to 2016 an increase of 90% of video content, 76% of gaming content, 36% VoIP, 36% file sharing being transmitted electronically. Hence it is legitimate to ask what role Linked Data takes in the content production process. Herein we can distinguish five sequential steps: 1) content acquisition, 2) content editing, 3) content bundling, 4) content distribution and 5) content consumption. As illustrated in the figure below Linked Data can contribute to each step by supporting the associated intrinsic production function [2].
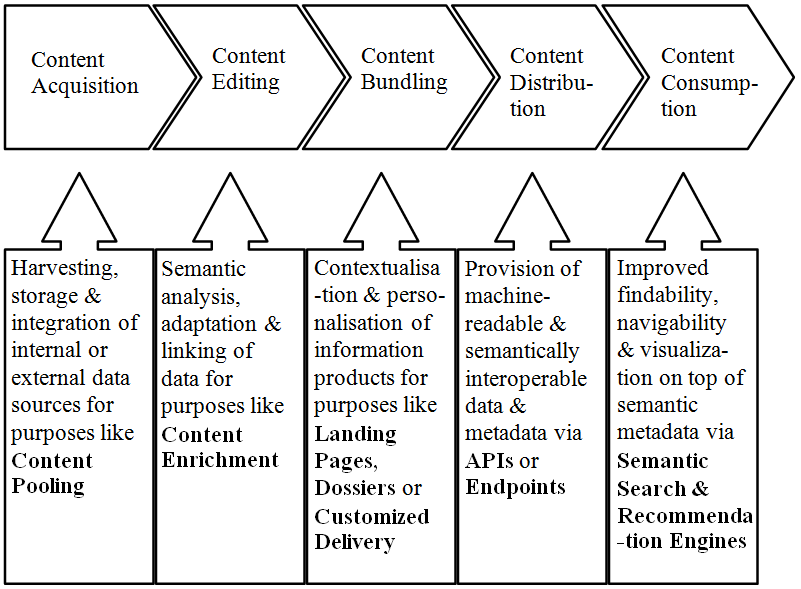
- Content acquisition is mainly concerned with the collection, storage and integration of relevant information necessary to produce a content item. In the course of this process information is being pooled from internal or external sources for further processing.
- The editing process entails all necessary steps that deal with the semantic adaptation, interlinking and enrichment of data. Adaptation can be understood as a process in which acquired data is provided in a way that it can be re-used within editorial processes. Interlinking and enrichment are often performed via processes like annotation and/or referencing to enrich documents either by disambiguating of existing concepts or by providing background knowledge for deeper insights.
- The bundling process is mainly concerned with the contextualisation and personalisation of information products. It can be used to provide customized access to information and services i.e. by using metadata for the device-sensitive delivery of content, or to compile thematically relevant material into Landing Pages or Dossiers thus improving the navigability, findability and reuse of information.
- In a Linked Data environment the process of content distribution mainly deals with the provision of machine-readable and semantically interoperable (meta-)data via Application Programming Interfaces (APIs) or SPARQL Endpoints. These can be designed either to serve internal purposes so that data can be reused within controlled environments (i.e. within or between organizational units) or for external purposes so that data can be shared between anonymous users (i.e. as open SPARQL Endpoints on the Web).
- The last step in the content value chain is dealing with content consumption. This entails any means that enable a human user to search for and interact with content items in a pleasant und purposeful way. So according to this view this step mainly deals with end user applications that make use of Linked Data to provide access to content items (i.e. via search or recommendation engines) and generate deeper insights (i.e. by providing reasonable visualizations).
Conclusion
There is definitely a place for Linked Data in the Content Value Chain, hence we can expect that Dynamic Semantic Publishing is here to stay. Linked Data can add significant value to the content production process and carry the potential to incrementally expand the business portfolio of publishers and other content-centric businesses. But the concrete added value is highly context-dependent and open to discussion. Technological feasibility is easily contradicted by strategic business considerations, a lack of cultural adaptability to legacy issues like dual licensing, technological path dependencies or simply a lack of resources. Nevertheless Linked Data should be considered as a fundamental principle in next generation content management as it provides a radically new environment for value creation.
More about the topic – live
Linked Data in the content value chain is also one of the topics set onto the agenda of this year’s SEMANTiCS 2014. Listen to keynote speaker Sofia Angeletou an others, to learn more about next generation content management.
References
[1] Auer, Sören (2011). Creating Knowledge Out of Interlinked Data. In: Proceedings of WIMS’11, May 25-27, 2011, p. 1-8
[2] Pellegrini, Tassilo (2012). Integrating Linked Data into the Content Value Chain: A Review of News-related Standards, Methodologies and Licensing Requirements. In: Presutti, Valentina; Pinto, Sofia S.; Sack, Harald; Pellegrini, Tassilo (2012). Proceedings of I-Semantics 2012. 8th International Conference on Semantic Systems. ACM International Conference Proceeding Series, p. 94-102
