With the rise of linked data and the semantic web, concepts and terms like ‘ontology’, ‘vocabulary’, ‘thesaurus’ or ‘taxonomy’ are being picked up frequently by information managers, search engine specialists or data engineers to describe ‘knowledge models’ in general. In many cases the terms are used without any specific meaning which brings a lot of people to the basic question:
What are the differences between a taxonomy, a thesaurus, an ontology and a knowledge graph?
This article should bring light into this discussion by guiding you through an example which starts off from a taxonomy, introduces an ontology and finally exposes a knowledge graph (linked data graph) to be used as the basis for semantic applications.
1. Taxonomies and thesauri
Taxonomies and thesauri are closely related species of controlled vocabularies to describe relations between concepts and their labels including synonyms, most often in various languages. Such structures can be used as a basis for domain-specific entity extraction or text categorization services. Here is an example of a taxonomy created with PoolParty Thesaurus Server which is about the Apollo programme:
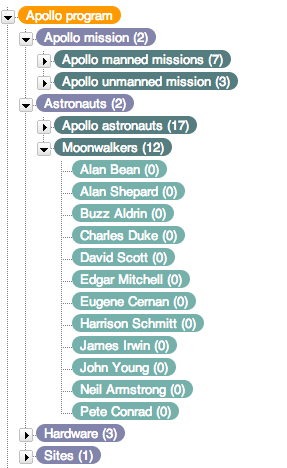 The nodes of a taxonomy represent various types of ‘things’ (so called ‘resources’): The topmost level (orange) is the root node of the taxonomy, purple nodes are so called ‘concept schemes’ followed by ‘top concepts’ (dark green) and ordinary ‘concepts’ (light green). In 2009 W3C introduced the Simple Knowledge Organization System (SKOS) as a standard for the creation and publication of taxonomies and thesauri. The SKOS ontology comprises only a few classes and properties. The most important types of resources are: Concept, ConceptScheme and Collection. Hierarchical relations between concepts are ‘broader’ and its inverse ‘narrower’. Thesauri most often cover also non-hierarchical relations between concepts like the symmetric property ‘related’. Every concept has at least on ‘preferred label’ and can have numerous synonyms (‘alternative labels’). Whereas a taxonomy could be envisaged as a tree, thesauri most often have polyhierarchies: a concept can be the child-node of more than one node. A thesaurus should be envisaged rather as a network (graph) of nodes than a simple tree by including polyhierarchical and also non-hierarchical relations between concepts.
The nodes of a taxonomy represent various types of ‘things’ (so called ‘resources’): The topmost level (orange) is the root node of the taxonomy, purple nodes are so called ‘concept schemes’ followed by ‘top concepts’ (dark green) and ordinary ‘concepts’ (light green). In 2009 W3C introduced the Simple Knowledge Organization System (SKOS) as a standard for the creation and publication of taxonomies and thesauri. The SKOS ontology comprises only a few classes and properties. The most important types of resources are: Concept, ConceptScheme and Collection. Hierarchical relations between concepts are ‘broader’ and its inverse ‘narrower’. Thesauri most often cover also non-hierarchical relations between concepts like the symmetric property ‘related’. Every concept has at least on ‘preferred label’ and can have numerous synonyms (‘alternative labels’). Whereas a taxonomy could be envisaged as a tree, thesauri most often have polyhierarchies: a concept can be the child-node of more than one node. A thesaurus should be envisaged rather as a network (graph) of nodes than a simple tree by including polyhierarchical and also non-hierarchical relations between concepts.
2. Ontologies
Ontologies are perceived as being complex in contrast to the rather simple taxonomies and thesauri. Limitations of taxonomies and SKOS-based vocabularies in general become obvious as soon as one tries to describe a specific relation between two concepts: ‘Neil Armstrong’ is not only unspecifically ‘related’ to ‘Apollo 11’, he was ‘commander of’ this certain Apollo mission. Therefore we have to extend the SKOS ontology by two classes (‘Astronaut’ and ‘Mission’) and the property ‘commander of’ which is the inverse of ‘commanded by’.
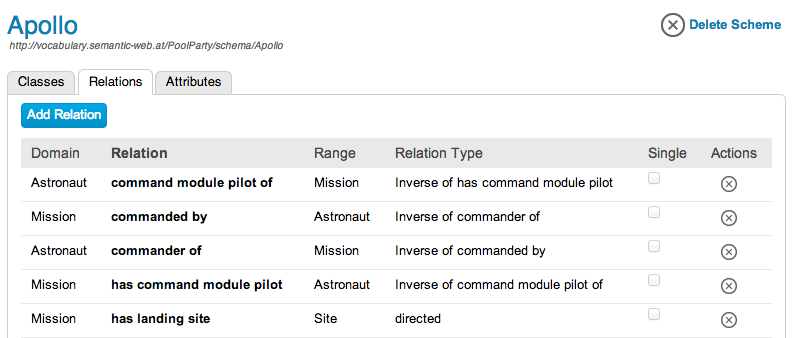 The SKOS concept with the preferred label ‘Buzz Aldrin’ has to be classified as an ‘Astronaut’ in order to be described by specific relations and attributes like ‘is lunar module pilot of’ or ‘birthDate’. The introduction of additional ontologies in order to expand expressivity of SKOS-based vocabularies is following the ‘pay-as-you-go’ strategy of the linked data community. The PoolParty knowledge modelling approach suggests to start first with SKOS to further extend this simple knowledge model by other knowledge graphs, ontologies and annotated documents and legacy data. This paradigm could be memorized by a rule named ‘Start SKOS, grow big’.
The SKOS concept with the preferred label ‘Buzz Aldrin’ has to be classified as an ‘Astronaut’ in order to be described by specific relations and attributes like ‘is lunar module pilot of’ or ‘birthDate’. The introduction of additional ontologies in order to expand expressivity of SKOS-based vocabularies is following the ‘pay-as-you-go’ strategy of the linked data community. The PoolParty knowledge modelling approach suggests to start first with SKOS to further extend this simple knowledge model by other knowledge graphs, ontologies and annotated documents and legacy data. This paradigm could be memorized by a rule named ‘Start SKOS, grow big’.
3. Knowledge Graphs
Knowledge graphs are all around (e.g. DBpedia, Freebase, etc.). Based on W3C’s Semantic Web Standards such graphs can be used to further enrich your SKOS knowledge models. In combination with an ontology, specific knowledge about a certain resource can be obtained with a simple SPARQL query. As an example, the fact that Neil Armstrong was born on August 5th, 1930 can be retrieved from DBpedia. Watch this YouTube video which demonstrates how ‘linked data harvesting’ works with PoolParty.
Knowledge graphs could be envisaged as a network of all kind things which are relevant to a specific domain or to an organization. They are not limited to abstract concepts and relations but can also contain instances of things like documents and datasets.
Why should I transform my content and data into a large knowledge graph?
The answer is simple: to being able to make complex queries over the entirety of all kind of information. By breaking up the data silos there is a high probability that query results become more valid.
With PoolParty Semantic Integrator, content and documents from SharePoint, Confluence, Drupal etc. can be tranformed automatically to integrate them into enterprise knowledge graphs.
Taxonomies, thesauri, ontologies, linked data graphs including enterprise content and legacy data – all kind of information could become part of an enterprise knowledge graph which can be stored in a linked data warehouse. Based on technologies like Virtuoso, such data warehouses have the ability to serve as a complex question answering system with excellent performance and scalability.
4. Conclusion
In the early days of the semantic web, we’ve constantly discussed whether taxonomies, ontologies or linked data graphs will be part of the solution. Again and again discussions like ‘Did the current data-driven world kill ontologies?‘ are being lead. My proposal is: try to combine all of those. Embrace every method which makes meaningful information out of data. Stop to denounce communities which don’t follow the one or the other aspect of the semantic web (e.g. reasoning or SKOS). Let’s put the pieces together – together!