Semantic Web Company and its PoolParty team are participating in the H2020 funded project ALIGNED. This project evaluates software engineering and data engineering processes in the context of how these both worlds can be aligned in an efficient way. All project partners are working on several use cases, which shall result in a set of detailed requirements for combined software and data engineering. The ALIGNED project framework also includes work and research on data consistency in PoolParty Thesaurus Server (PPT).
ALIGNED: Describing, finding and repairing inconsistencies in RDF data sets
When using RDF to represent the data model of applications, inconsistencies can occur. Compared with the schema approach of relational databases, a data model using RDF offers much more flexibility. Usually, the application’s business logic produces and modifies the model data and, therefore, can guarantee the consistency needed for its operations. However, information may not only be created and modified by the application itself but may also originate from external sources like RDF imports into the data model’s triple store. This may result in inconsistent model data causing the application to fail. Therefore, constraints have to be specified and enforced to ensure data consistency for the application. In Phase 1 of the ALIGNED project, we outline the problem domain and requirements for the PoolParty Thesaurus Server use case with the goal of establishing a solution for describing, finding and repairing inconsistencies in RDF data sets. We propose a framework as a basis for integrating RDF consistency management into PoolParty Thesaurus Server software components. The approach is a work in progress that aims for adopting technologies developed by the ALIGNED project partners and refine them for usage in an industrial-strength application.
Technical View
Users of PoolParty often wish to import arbitrary datasets, vocabularies, or ontologies. But these datasets do not always meet these constraints PoolParty impose. Currently, when users attempt to import data which violates the constraints, the data will simply fail to display, or in the worst case, cause unexpected behaviour and lead to/reflect errors in the application. Enhanced PoolParty will feedback the user why the import has failed, suggest ways in which the user can fix the problem and also identify potential new constraints that could be applied to the data structure. Apart from the import functionality, different other software components, like the taxonomy editor, or the reasoning engine drive RDF data constraints and vice versa. The following figure outlines utilization and importance of data consistency constraints in the PoolParty application:
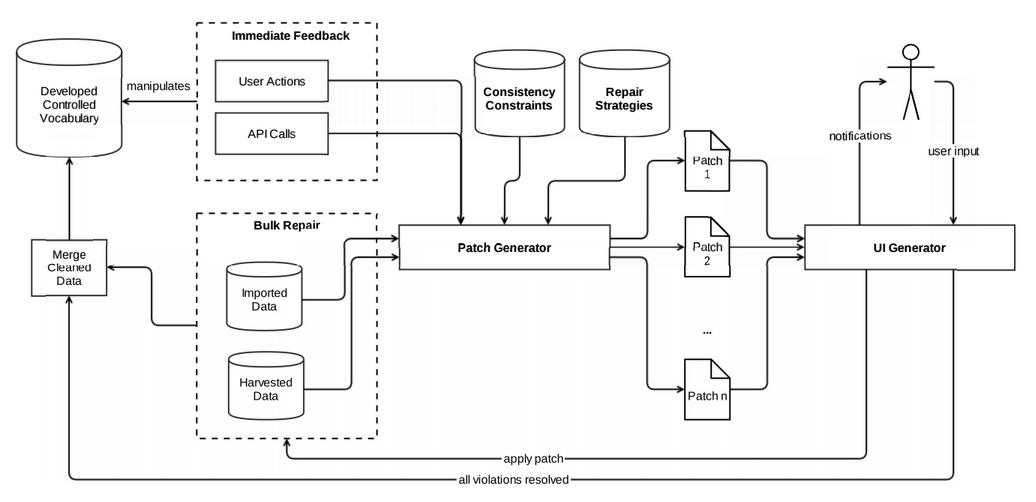
Approaches and solutions for many of these components already exist. However, the exercise within ALIGNED is to integrate them in an easy-to-use way to comply with the PoolParty environment. Consistency constraints, for example, can be formulated using RDF Data Shapes or interpreting RDFS/OWL constructs with constraints-based semantics. RDFUnit already partly supports these techniques. Repair strategies and curation interfaces are covered by the Seshat Global History Databank project. Automated repair of large datasets can be managed by the UnifiedViews ETL tool, whereas immediate notification on data inconsistencies can be disseminated via the rsine semantic notification framework.
Outlook
Within the ALIGNED projects, all project partners demand simple (i.e. maintainable and usable) data quality and consistency management and work on solutions to meet their requirements. Our next steps will encompass research on how to apply these technologies to the PoolParty problem domain, and to take part in unifying and integrating the different existing tools and approaches. The immediate challenge to address will be to build an interoparable catalog of formalized PoolParty data consistency constraints and repair strategies so that they are machine-processable in a (semi-)automatic way.