There is a strong connection between information storage and retrieval, namely how information storage is implemented under the hood directly impacts the retrieval or search.
The knowledge management techniques we adopt have an immense impact on our daily productivity. For that reason, a lot of thought is given by us when we store information, asking questions such as which tools we should use for the very same purpose.
In this blog post, we will see the reasons behind why PoolParty GraphSearch is a very powerful semantic search tool, but before dwelling into that we go back to an old-school method of knowledge management called “Zettelkasten”.
Zettelkasten
Niklas Luhmann developed his own system of knowledge management back in the time called “Zettelkasten” (“slip notes” in English). His method allowed him to be highly productive when working with literature as a scientist. The system is mostly known to librarians, but can also be used as a standalone system for storing information, ideas, book excerpts and so on.
Using this system, as shown in the following figure, in principle one can store handwritten slip notes in “index card” format by giving an Identifier, body text describing the slip note, as well as related slip notes by referencing them with their corresponding Identifier. After that, one decides in which category she should put the slip note. In this way, one can look over all slip notes of Category A, and while looking into that information she can jump to other slip notes of Category B or C. This is a powerful way to search/browse for information and how one can come up with relevant slip notes by just starting somewhere.
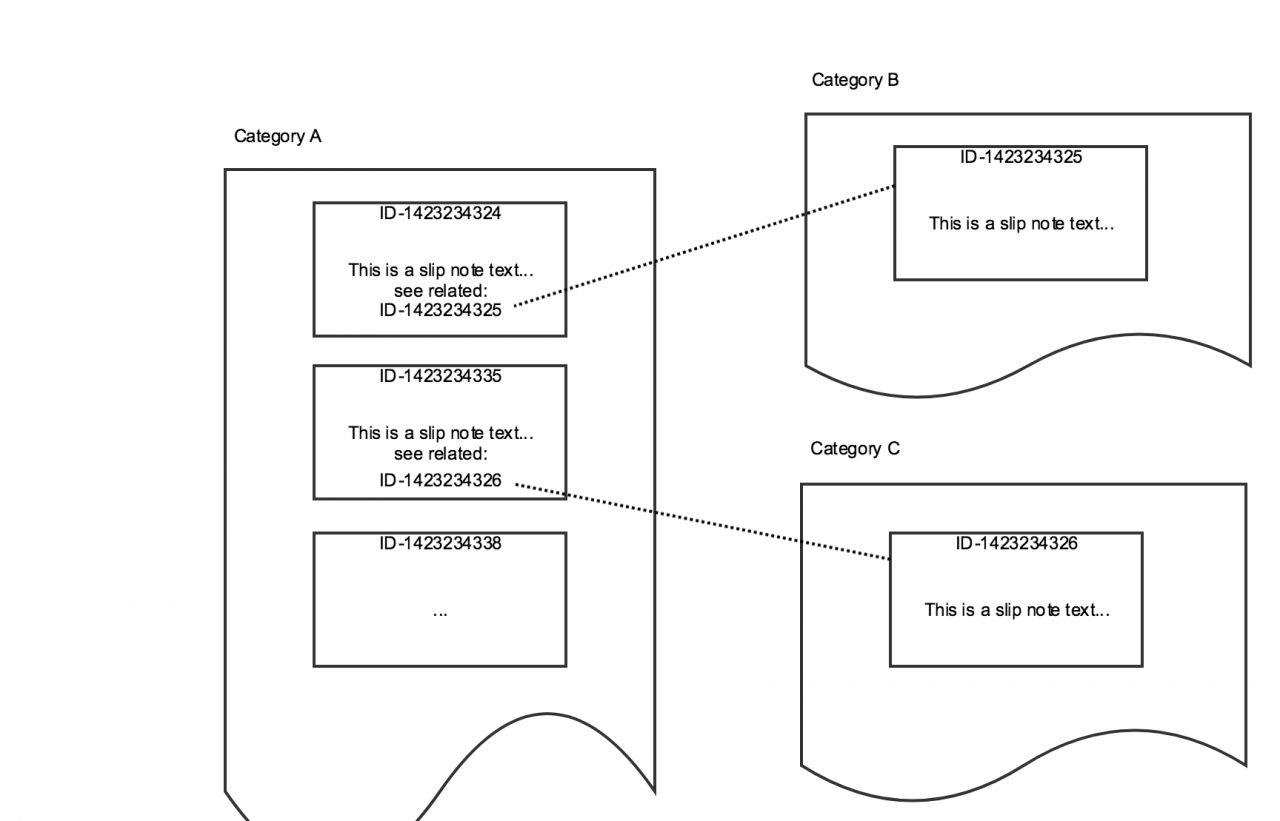
Imagine you have an index card categorized as “Da Vinci”, “Renaissance” and you have the <body text>, plus indices (pointers) to related index cards such as “related events”, or “museums”. By looking at categories “Da Vinci”, “Renaissance” this system is able to retrieve you the “related events” and bring you to a new piece of information that you never thought of previously. From the perspective of search — in this system one can either “branch” further via categories, or “chase” using pointers to related index cards. By combining “branch” and “chase” one can find information that on first look appeared disconnected, but turned out to be a very relevant information.
Graph data in RDF
From the previous figure one can see that the structure of the information in Zettelkasten can be visualized as a graph. Thus, one starts with a node and then follows edges until the search criteria according to her is satisfied, or alternatively she decides to stop.
The most prominent way of storing the graph data is in RDF, while querying them using SPARQL. The graph data is stored in a triple format consisted of subject, predicate (or property) and object; each one of them having an URI identifier. Having URIs in place, using RDF it is much easier to integrate and link data from different sources. On other hand, SPARQL is very expressive language – as expressive as SQL – and one can use it to query and traverse data in the graph. While SPARQL is a great query and manipulation language for graphs, is not that user-friendly to a broad of users. For that reason, different Semantic Web applications are created with that in mind so that they generate SPARQL queries under the hood, initially having an original query in a different format such as natural language or facets.
Faceted search is widely used today (for instance, see Amazon) as a means to drill-down search criteria by allowing users to select the relevant boxes as search criteria in a very intuitive way. Nowadays, Semantic Web applications mimic the same functionality on top of RDF graph data, where SPARQL queries are generated on the background while users select different combination of facets.
PoolParty GraphSearch (PPGS)
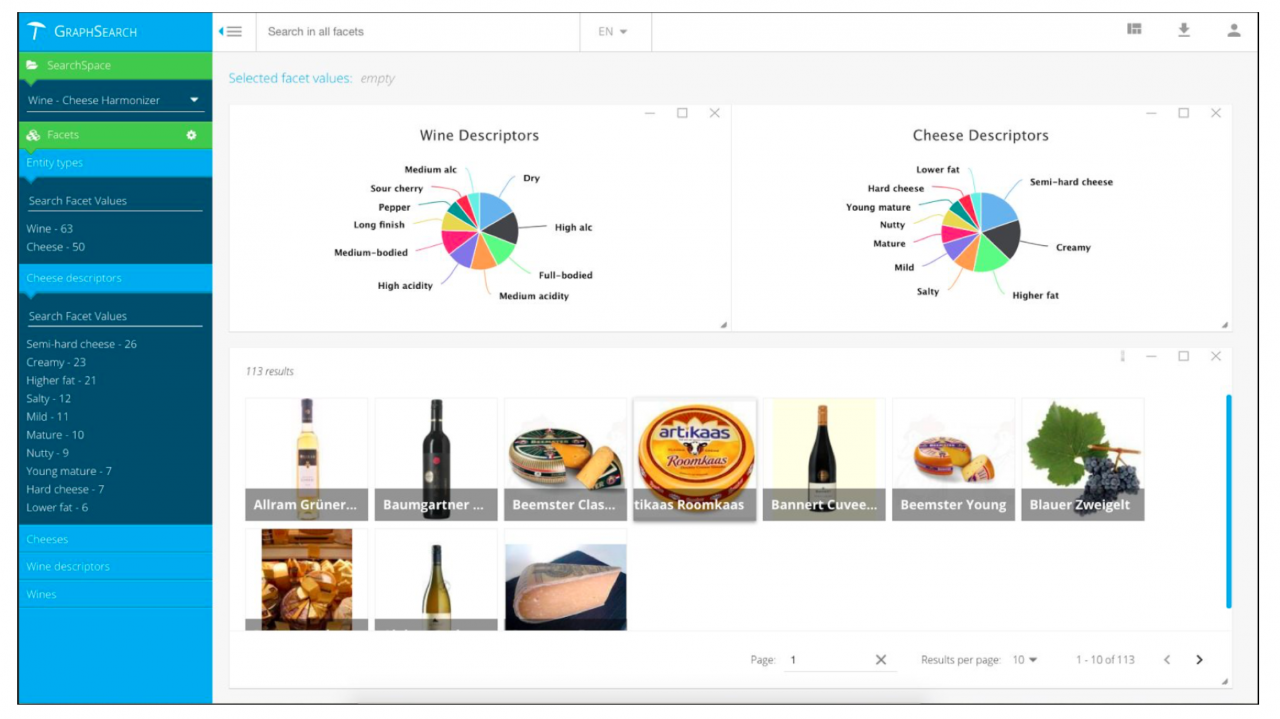
PoolParty GraphSearch is a semantic search application, an analytical tool that allows users to search for information using facets. Search is done via facets of concepts and properties, derived from a PoolParty thesaurus, that drill-down information satisfying the criteria.
In PoolParty GraphSearch, such information is a-priori annotated using PoolParty Extractor using concepts and properties from the designated thesaurus. The workflow of annotating is typically done using UnifiedViews DPUs (Data Processing Unit), and in the end the triples are stored in a dedicated triple store; where then are fed to GraphSearch.
In PPGS one not only can find information based on facets, but also based on content similarity, and the system allows to plug in any kind of other similarity algorithm and thus build any custom recommender engine (for instance see Wine and Cheese recommender). On top of that, in PPGS one can also visualize different statistics based on actual data using pie charts or histograms.
Connection between PPGS and Zettelkasten
As mentioned earlier the Zettelkasten method can be conceptualized as a graph, and this allows us to make a direct connection with PPGS.
Zettelkasten technique can be implemented in PoolParty GraphSearch, where:
- categorized search is done via facets, i.e., dereferencable concepts <http://dbpedia.org/page/Leonardo_da_Vinci>, <http://dbpedia.org/page/Category:Renaissance>.
- regarding related index cards, instead of pointers we have typed links, i.e. dereferencable properties such as <http://dbpedia.org/ontology/museum>
- for related index cards, we can also use the similarity feature where we get similarity results based on the <content>.
Clearly, in PoolParty GraphSearch 2) and 3) bring Zettelekasten technique to a new level, while 1) makes the approach in general more robust, i.e., representing data using “things” and not “strings”.
Conclusion
Lately, in order to honour Niklas Luhmann, there was an initiative to convert all his Zettelkasten in XML (link only in German). If we would have such Zettelkasten in XML, by converting them to RDF (for instance using UnifiedViews), then ultimately we would see the fundamental advantage of PoolParty GraphSearch.