In a previous blog post I have discussed the power of SPARQL to go beyond data retrieval to analytics. Here I look into the possibilities to implement a product recommender all in SPARQL. Products are considered to be similar if they share relevant characteristics, and the higher the overlap the higher the similarity. In the case of movies or TV programs there are static characteristics (e.g. genre, actors, director) and dynamic ones like viewing patterns of the audience.
The static part of this we can look up in resources like the DBpedia. If we look at the data related to the resource <http://dbpedia.org/resource/Friends> (that represents the TV show “Friends”) we can use for example the associated subjects (see predicate dcterms:subject). In this case we find for example <http://dbpedia.org/resource/Category:American_television_sitcoms> or <http://dbpedia.org/resource/Category:Television_shows_set_in_New_York_City> If we want to find other TV shows that are related to the same subjects we can do this with the following query:
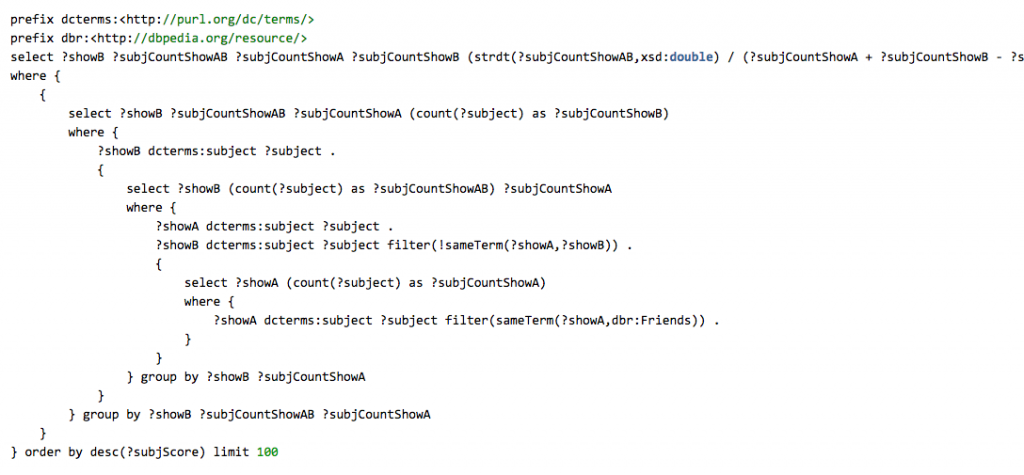
- Count the number of subjects related to TV show “Friends”.
- Get all TV shows that share at least one subject with “Friends” and count how many they have in common.
- For each of those related shows count the number of subjects they are related to.
- Now we can calculate the relative overlap in subjects which is (number of shared subjects) / (numbers of subjects for “Friends” + number of subjects for other show – number of common subjects).
This gives us a score of how related one show is to another one. The results are sorted by score (the higher the better) and these are the results for “Friends”:
|
showB
|
subjCount ShowAB
|
subjCount ShowA
|
subjCount ShowB
|
subj Score
|
|---|---|---|---|---|
| Will_&_Grace | 10 | 16 | 18 | 0.416667 |
| Sex_and_the_City | 10 | 16 | 21 | 0.37037 |
| Seinfeld | 10 | 16 | 23 | 0.344828 |
| Veronica’s_Closet | 7 | 16 | 12 | 0.333333 |
| The_George_Carlin_Show | 6 | 16 | 9 | 0.315789 |
| Frasier | 8 | 16 | 18 | 0.307692 |
In the fist line of the results we see that “Friends” is associated with 16 subjects (that is the same in every line), “Will & Grace” with 18, and they share 10 subjects. That results into a score of 0.416667. Other characteristics to look at are actors starring a show, the creators (authors), or executive producers.
We can pack all this in one query and retrieve similar TV shows based on shared subjects, starring actors, creators, and executive producers. The inner queries retrieve the shows that share some of those characteristics, count numbers as shown before and calculate a score for each dimension. The individual scores can be weighted, in the example here the creator score is multiplied by 0.5 and the producer score by 0.75 to adjust the influence of each of them.

This results into:
|
showB
|
subj Score
|
star Score
|
creator Score
|
execprod Score
|
integrated Score
|
|---|---|---|---|---|---|
| The_Powers_That_Be_(TV_series) | 0.17391 | 0.0 | 1.0 | 0.0 | 0.1684782608 |
| Veronica’s_Closet | 0.33333 | 0.0 | 0.0 | 0.428571 | 0.1636904761 |
| Family_Album_(1993_TV_series) | 0.14285 | 0.0 | 0.666667 | 0.0 | 0.1190476190 |
| Jesse_(TV_series) | 0.28571 | 0.0 | 0.0 | 0.181818 | 0.1055194805 |
| Will_&_Grace | 0.41666 | 0.0 | 0.0 | 0.0 | 0.1041666666 |
| Sex_and_the_City | 0.37037 | 0.0 | 0.0 | 0.0 | 0.0925925925 |
| Seinfeld | 0.34482 | 0.0 | 0.0 | 0.0 | 0.0862068965 |
| Work_It_(TV_series) | 0.13043 | 0.0 | 0.0 | 0.285714 | 0.0861801242 |
| Better_with_You | 0.25 | 0.0 | 0.0 | 0.125 | 0.0859375 |
| Dream_On_(TV_series) | 0.16666 | 0.0 | 0.333333 | 0.0 | 0.0833333333 |
| The_George_Carlin_Show | 0.31578 | 0.0 | 0.0 | 0.0 | 0.0789473684 |
| Frasier | 0.30769 | 0.0 | 0.0 | 0.0 | 0.0769230769 |
| Everybody_Loves_Raymond | 0.30434 | 0.0 | 0.0 | 0.0 | 0.0760869565 |
| Madman_of_the_People | 0.3 | 0.0 | 0.0 | 0.0 | 0.075 |
| Night_Court | 0.3 | 0.0 | 0.0 | 0.0 | 0.075 |
| What_I_Like_About_You_ (TV_series) |
0.25 | 0.0 | 0.0 | 0.0625 | 0.07421875 |
| Monty_(TV_series) | 0.15 | 0.14285 | 0.0 | 0.0 | 0.0732142857 |
| Go_On_(TV_series) | 0.13043 | 0.07692 | 0.0 | 0.111111 | 0.0726727982 |
| The_Trouble_with_Larry | 0.19047 | 0.1 | 0.0 | 0.0 | 0.0726190476 |
| Joey_(TV_series) | 0.21739 | 0.07142 | 0.0 | 0.0 | 0.0722049689 |
Each line shows the individual scores for each of the predicates used and in the last column the final score. You can also try out the query with “House” <http://dbpedia.org/resource/House_(TV_series)> or “Suits” <http://dbpedia.org/resource/Suits_(TV_series)> and get shows related to those.
This approach can be used for any similar data, too, where we want to obtain similar items based on characteristics they share. One could for example compare persons (by e.g. profession, interests, …), or consumer electronic products like photo cameras (resolution, storage, size or price range).