Semantic Enterprise Search enters the second phase.
Finally the Knowledge Graph has arrived in Europe: What has been provided on google.com for the US-Market since May 2012, is now available also for most European countries. Search results are no longer only a list of documents (and advertisements) but also a mashup of facts, points of interest, events etc. referring to the search phrase.
For example, if the user is searching for ‘Wiener Philharmoniker’ (‘Vienna Philharmonic Orchestra’) a factbox including related searches is provided:
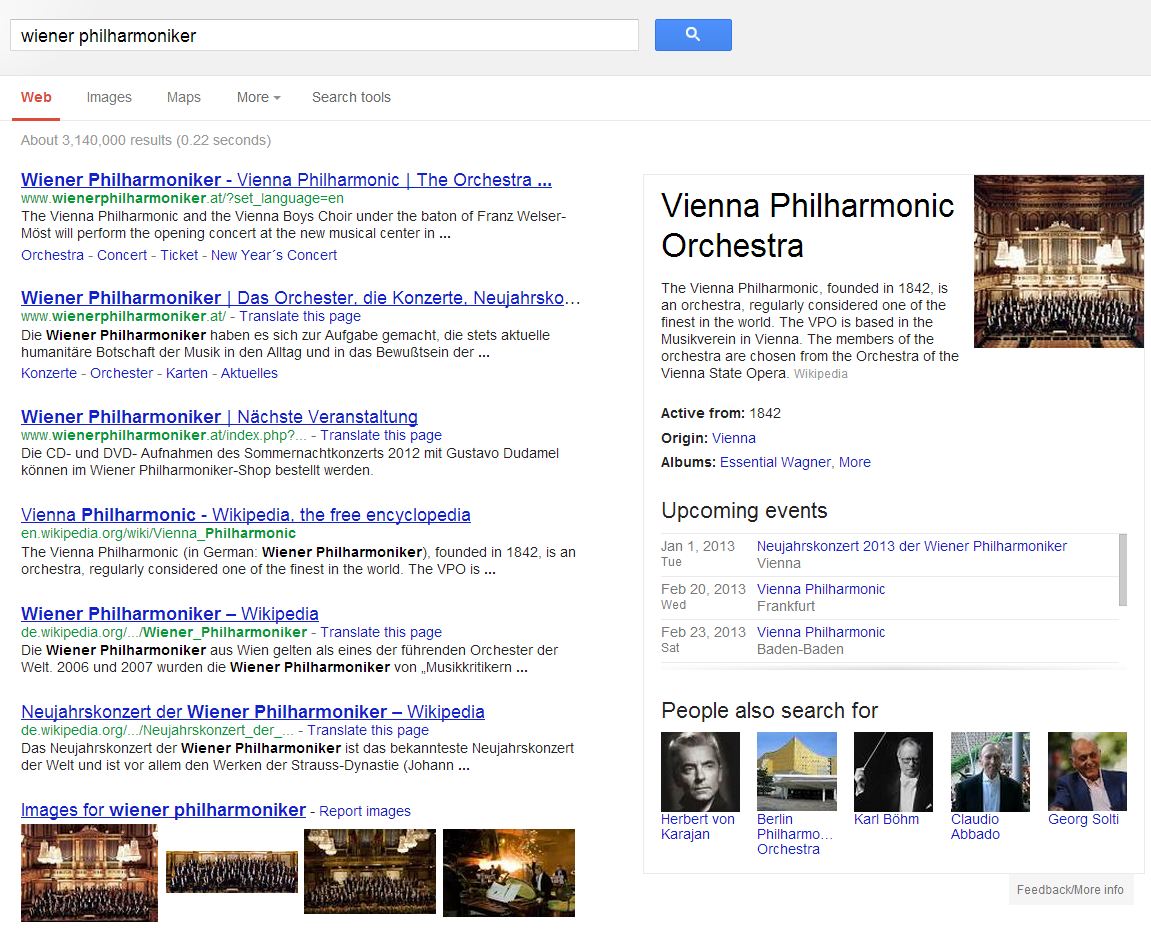
Do you like this rather new way of knowledge discovery? We do, except the fact that Google hasn´t properly explained to the audience which technology is behind the Knowledge Graph which is the Web of Linked Data aka the Semantic Web (Do you want to know more about the relationship between the Knowledge Graph and Linked Data? Click here).
But anyway, here are some benefits we can see, if search technologies make use of a ‘knowledge graph’, a ‘knowledge model’, a ‘thesaurus’ or generally spoken: Linked Data.
- Facts around an object (or an entity) can be found nicely packed up to a dossier
- Serendipity can be stimulated by ‘related searches’ which means: Users can discover the formely ‘unknown’ in a more comfortable way
- Data from various sources can be pulled together to a mashup (e.g. ‘upcoming events’ could come from a different database than the basic facts of Vienna Philharmonic Orchestra)
- Search phrases are well understood by the engine since they are based on concepts and not anymore on literals, e.g. if the user searches for ‘Red Bull Stratos’, also results for ‘Felix Baumgartner’ will be delivered
- Search can be refined, e.g. if one searches for ‘Vienna’, a list of POIs will be displayed to refine the actual place the user is looking for
Now imagine you would have a search engine in your company’s intranet based on a knowledge graph which is about the enterprise you are working for.
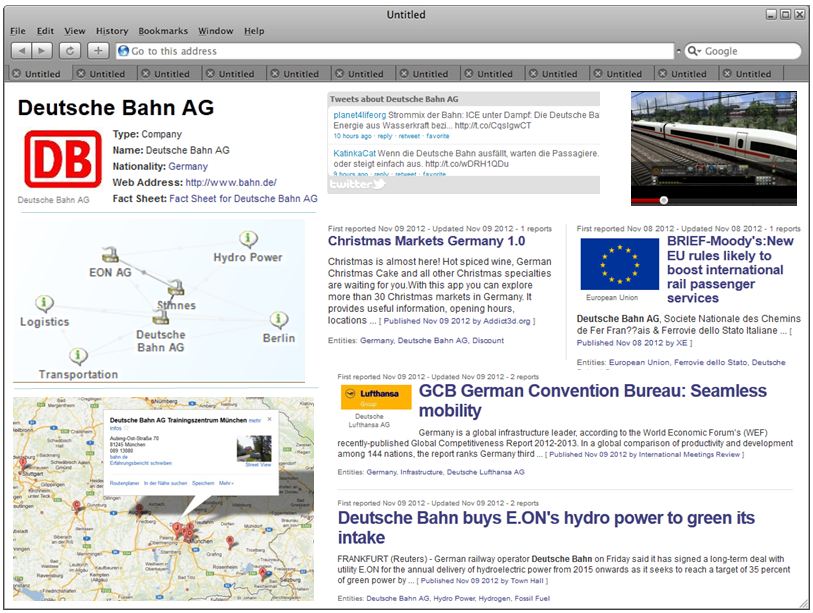 Such an advanced search application would look like this:
Such an advanced search application would look like this:
- Data streams and all kind of content from internal sources are nicely mashed with information from the web (e.g. from Twitter, Youtube etc.)
- Search assistants are provided to help users to refine their information needs to make them more specific
- Entities and their sub-concepts (e.g. subsidiaries of large companies or regions of countries) are nicely packed together to one dossier
The key question now is: “how to set up a customised knowledge graph for a certain company?”.
