Let me show you which steps have to be taken to generate a high-quality text mining application, ready to be used to annotate and to categorize any kind of text or documents covering nearly any domain. With our approach of thesaurus based text mining your documents can also be linked to the world of linked (open) data; enrich your documents with data from the LOD cloud!
Step 1. Generate a thesaurus by using a linked data source like DBpedia
As recently reported SWC has developed a tool called SKOSsy which can be used to extract seed thesauri from DBpedia. In our example I will generate a knowledge model describing the domain of “digital photography“. This step took around 15 minutes.
![]()
Step 2. Load the thesaurus into PoolParty and improve it to your needs
After the seed thesaurus has been loaded into PoolParty Thesaurus Manager you have many possibilities to enhance the knowledge model further: Add more categories, synonyms, relations etc. In this example I use the seed-thesaurus without any further improvements. This step took approximately 2 minutes.
Step 3. Generate an automatic text extractor on top of your thesaurus
This step took a couple of seconds and ended up in having generated a fast and reliable text mining application on top of PoolParty Extractor, ready to be used to enrich your documents with data from the LOD cloud.
You can try it out here: PPX Live-Demo
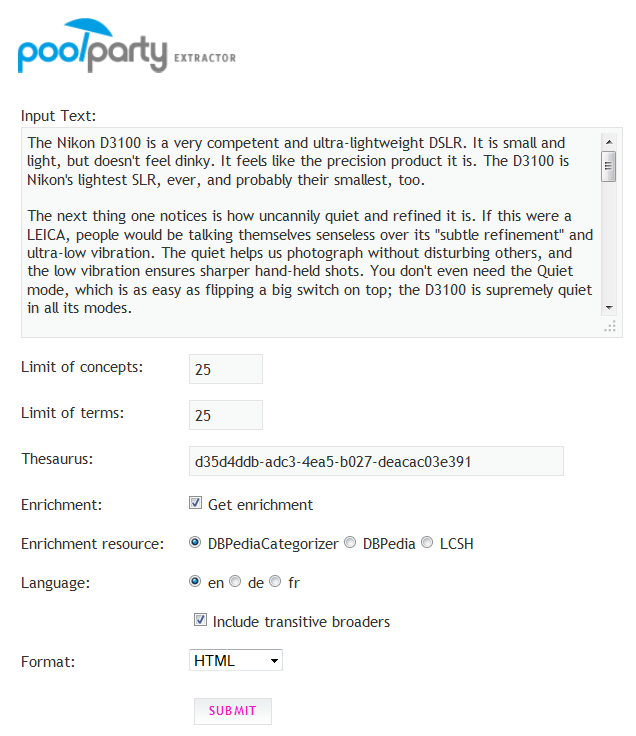
To try the extractor on your own, please take a look at the image above which shows a proper configuration, you have to insert the following UUID in the form: d35d4ddb-adc3-4ea5-b027-deacac03e391
Since our example is all about ‘digital photography’, we recommend to use text samples (or some fragments) like these ones to test the quality of PPX based text analytics:
- Digital Camera Image Noise (Results as HTML, RDF/XML)
- Nikon D3S In-depth Review (Results as HTML, RDF/XML)
- Introduction to Shutter Speed in Digital Photography (Results as HTML, RDF/XML)
- Digital Camera Sensors (Results as HTML, RDF/XML)
Let us know what you think about this straight-forward approach and your opinion about the quality of the results. We believe that thesaurus based text mining is in many cases an alternative to some other approaches, especially if you want to to enrich your content with information from the upcoming web of data.
Of course we would be happy to generate other demos in the areas of your interest! Just get in contact with us by using our contact form.