As a matter of fact things change – the Web of Data is no exception in that respect. While some sources, such as Twitter, are intrinsically dynamic, others change every now and then, potentially in unforeseeable intervals. In the recent Talis Nodalities Magazine, we made a case for Keeping up with a LOD of changes; here I’m going to elaborate a bit more on the current state of Dataset Dynamics and its challenges.
Let us first step a back a bit and have a look what Dataset Dynamics are and why this is important. In the Web of Linked Data we typically deal with datasets, for example, from the biomedical domain or the media industry on the one hand, and entities, such as a certain protein or people on the other. For the entity-level case established HTTP caching mechanism can be leveraged (see the Caching Tutorial and Things Caches Do). Further, with Memento, a HTTP-based versioning mechanisms has been proposed as well as implemented, adding a “time dimension” to HTTP (see Fig. 1).
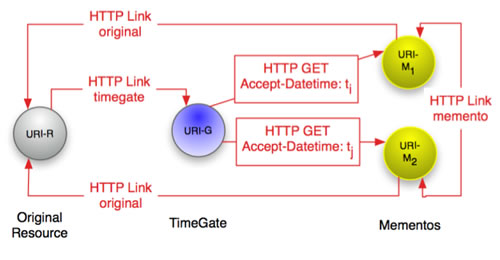
Dataset-level changes
However, tackling dataset-level changes is a rather new field with no agreed-upon, even less standardised solution handy. The main problem is that a dataset typically talks about many thousands to millions of distinct entities, which makes it impractical to apply entity-level solutions for a range of use cases, such as link maintenance or replication (see also Fig. 2).
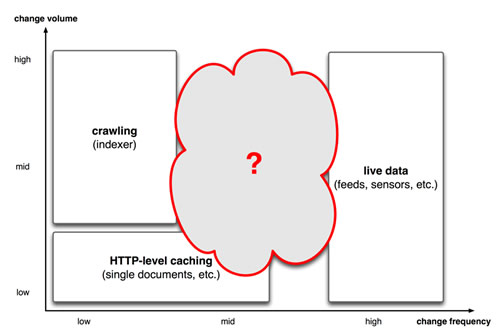
I often hear these days: “it seems there is no solution for handling of dataset-level changes”; nevertheless, I think quite the opposite it true. There are plenty of proposed solutions from both the academia and practitioners, targeting different challenges in the areas of:
- Change discovery – how do I find out about about dataset changes?
- Propagating changes – if there is a change, how is the change communciated to a consumer?
- Change semantics – how do I learn what has changed (has been added, removed, etc.)?
Some proposals on the table are integrated approaches (such as DSNotify, SemanticPingback, Talis Changeset) while others focus on certain aspects (like the dady vocabulary for discovery or the Graph Update Ontology for change semantics) or deal concrete environments, for example sparqlPuSH for SPARQL enpdoints.
A Dataset Dynamics Manifesto
No matter on what (set of) solutions the community eventually agrees on to address the handling of dataset-level changes, it should adhere to the following principles:
- light-weight
- distributed and scalable
- standards-based
Obviously, a light-weight (and ideally RESTful) approach lowers the barriers to adoption and enables a quick uptake. When I say light-weight, I mean it both in terms of protocol and code. It should be easy to integrate in RDF stores and libraries and available in all common Web programming languages including but not limited to Java, PHP, .NET family, etc.
Just as the Web of Data is a globally distributed dataspace, handling of changes should be done in a distributed fashion. There will be many different publishers and consumers (such as agents, indexer, consolidator platforms, etc.) of datasets with different requirements and capabilities. A distributed approach can cope with this challenge in a cost- and performance-efficient way. Tightly connected to this: It has to scale. Today, we’re dealing with some hundreds of LOD datasets. In the next couple of years, this will likely explode into the millions and hence one needs to be able to deal with such a growth. The same, just sooner, is true for the number of consumers of the changes.
Last but not least the Dataset Dynamics solution should be based on standards. It doesn’t necessarily need to be RDF for all of the challenges as outlined above. For example, Atom offers a standardised, extensible and widely accepted format to propagate changes; to take this further Pubsubhubbub can be utilised to enable a standardised, distributed publisher-subscriber scheme (Fig 3.)
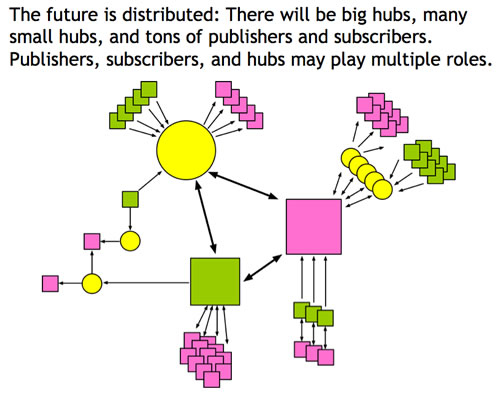
As I’ve outlined above, it might still be too early for a conclusion on how to deal with dataset-level changes. However, people interested in this area have gathered already in the Dataset Dynamics group where solutions are discussed and implemented, potentially leading to a W3C standardisation work.
As an aside: in case you’re at the WWW2010 in Raleigh (NC, USA) these days, you may want to join the break-out meeting on Dataset Dynamics during the W3C Linked Open Data track on 29 April 2010.
(This blog post was written by Michael Hausenblas)