Introduction
Knowledge Graphs (KGs) are currently on the rise. In their latest Hype Cycle for Artificial Intelligence (2018), Gartner highlighted:
“The rising role of content and context for delivering insights with AI technologies, as well as recent knowledge graph offerings for AI applications have pulled knowledge graphs to the surface.”
We can roughly divide KGs into 2 categories:
One of the differences between the two categories is that the expert KGs contain strict knowledge accepted in the expert community of their respective domain. On the contrary, for general purposes, KGs need a vast amount of common sense knowledge that is provided by non-expert users that is not necessarily strictly validated.
In this blog post, we introduce a novel crowdsourcing approach to extend general-purpose knowledge graphs based on a human-in-the-loop model. Using automatic reasoning mechanisms inspired by belief-revision, our approach incorporates views of different users, extracts the largest subgraph without contradictions and integrates this subgraph into the KG. Users can provide their updates in an intuitive way without requiring expertise in the knowledge already contained in the graph.
We have implemented and deployed the approach at PROFIT platform. PROFIT is a public platform for promoting financial awareness, hence everyone is welcome to contribute to the PROFIT financial knowledge graph that currently contains more than 11.000 concepts in 26 languages.
Related Work
One of the most important parts of the KGs is the hierarchy of classes of the domain of discourse. The most popular approach in the area of crowdsourcing (OWL) class hierarchies relies on exemplifying concepts (Exemplifying approach).
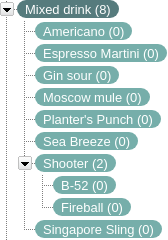
Example. “B-52” is a “Shooter” and a “Mixed drink”, so is “Fireball”. “Sea Breeze” is a “Mixed drink”, but not a “Shooter”, hence “Shooter” is more specific than “Mixed drink”.
The advantage of the exemplifying approach is that any discussion about the particular structure of the resulting hierarchy can always be resolved by presenting new examples or discussing the old ones. It is adopted in several crowdsourcing frameworks, for example, CASCADE and CuriousCat.
However, this process is indirect in the sense that users operate on individuals, but get information about classes as the result. This aspect might be confusing for the non-expert users. Moreover, it might be easier to operate on classes directly rather than presenting a number of individuals. To overcome these issues we designed a process of “direct” crowdsourcing, where users operate on classes and obtain a hierarchy of classes as the outcome.
From Direct Beliefs to Knowledge
The challenges of crowdsourcing the taxonomies directly are the following:
- How to guarantee the absence of internal contradictions? For example, A <= B <= C <= A.
- How to take the different non-compliant inputs into account?
- How to integrate the crowdsourced knowledge?
We tackle these challenges in Belief Revision manner. In the following figure, we outline the method.
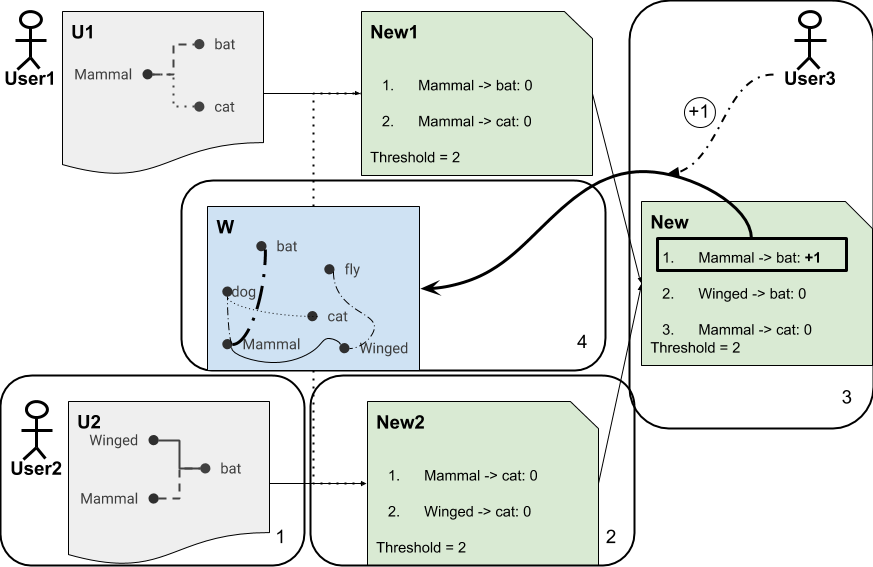
We have 4 steps in our process:
- [Collect (box 1)] The user provides their beliefs / updates. The user chooses freely which entities he operates on: no prepared questions or other constraints.
- [Analyze and Provide Feedback (box 2)] The user’s update is analyzed against the existing knowledge graph. The users receive feedback about any internal inconsistencies inside their update in real time.
- [Vote (box 3)] The users vote on triples suggested by other users. Users either vote explicitly on a dedicated page or implicitly in case their update overlaps / confirms an update from a different user.
- [Integrate (box 4)] The threshold for accepting an update is computed dynamically when the update is submitted and depends on how well the update complies with the existing knowledge. When an update gets the numbers of upvotes equal to this threshold, the knowledge is integrated into the existing knowledge graph.
Conclusion
We introduce a novel crowdsourcing approach. The main features are:
- The users work directly with the hierarchy of classes, not any other entities.
- No need to have the information about the existing knowledge to provide new input. Hence, suitable for large KGs.
- The power of reasoning mechanisms of the semantic web is used to analyze user’s inputs, estimate its quality, avoid contradictions. The tool is also able to provide this feedback to educate the user.